Relational Model Concepts
The model was first proposed by Dr. E.F. Codd of IBM in 1970 in the following paper
Dr.E.F.Codd가 논문으로 1970년 처음발표Relational Model은 Database가 relation들의 집합이라고 정의를 내림. (테이블과 비슷한 개념)

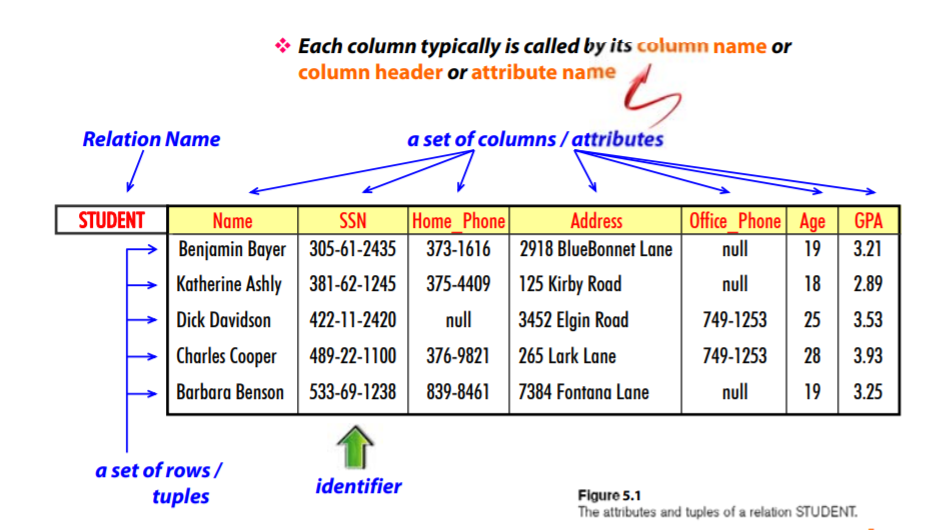
Relation : 값들의 표를 나타냄
행의 집합과 열의집합으로 구성
각각의 행은 구분해줄수 있는 식별자로 구성되어있고
각각의 열은 전형적으로 컬럼제목, 헤더, attribute name을 갖고 구분할수 있게끔 되어있다.
DOMAINS, ATTRIBUTES, TUPLES, RELATIONS
Domain : 각각의 컬럼은 그 컬럼에 들어갈수 있는 값의 범위가 정해져있다. (원자(나누어질수 없는)값의 집합)
-도메인을 구성하는 값들의 데이터 타입을 명세함으로서 도메인과 Attribute를 정의한다.
-도메인에는 그 도메인을 갖는 attribute, attribute의 type, type들의 format 을 갖추고있다.
STUDENT(Name, Ssn, Home_phone, Address, Office_phone, Age, Gpa)
Student라는 relation은 ( ...의 attribute를 가짐)
Relation schema (scheme): R (A1, A2, ..., An)= >relation의 구조를 보여주는것을 relation schema라고 함.
-각 attribute는 그 attribute가 정의되는 도메인이 존재하며, 아무값이나 갖는것이 아닌 도메인 내부의 한가지 값을 갖는것이다.
ex) attribute가 Age라면 Age가 정의된 범위인 15~80 사이의 값으로 정해진다.
-relation의 attribute개수가 n이라면 relation의 n차수라고 부른다.



Formal Definition
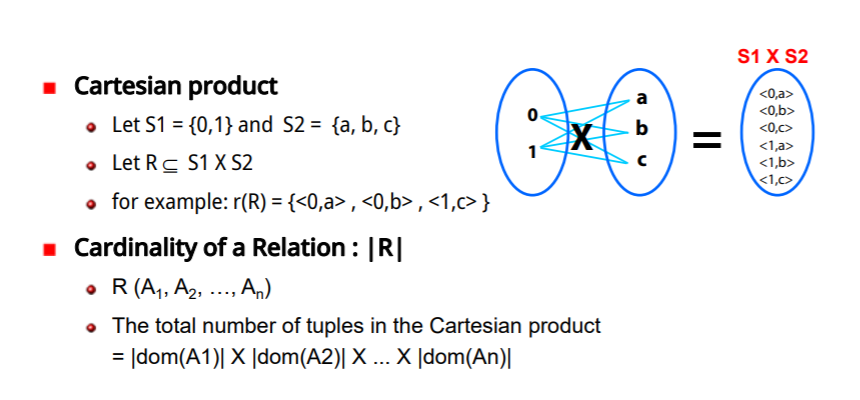
A relation (or relation state) r of the relation schema R (A1, A2, …, An)
r(R)이라는 것은 n차수 tuple의 ti행을 말한다 : r = { t1,t2...}
n차수 tuple의 각 행 t는 또한 형태의 t=<v1,v2...> 형태의 attribute 값의 순서리스트로 정의된다.

정형적으로, R(A1,A2,...,An)에서
r(R)은 domain(A1)Xdom(A2)..Xdom(An))의 카티션 프로덕트(두 개의 테이블에서 각각의 레코드들을 서로 결합하여 하나의 레코드로 구성하면서 가능한 모든 조합의 레코드들로 테이블을 만드는 연산) 의 부분집합이며
-R :은 relation의 Schema이자 intension of a realtion이라고 불리며
-r : 은 특정 값이나 적재된 모습이라 얘기하며 - relation, relation state, relation instance라고도 하며
extension of a realtion이라고 불린다.


Characteristics of Relations
-relation의 튜플들에 순서가 있는가 물으면 , 원래 relation은 튜플들의 집합이며 집합은 순서의 개념을 갖지 않는다.

-tuple은 attribute의 순서리스트로 정의되나 조금더 General한 정의를 하면 tuple은 attribute들의 집합으로 정의가 가능하다.
-즉 relation schema : R(A1,A2...An) 은 Attributed의 집합으로 정의되므로 순서의 개념을 갖지 않는다.

Values and NULLs in the tuples
relation에 나타나는 모든 값들은 atomic한 값이다.
-composite, multivalued한 attribute들은 허용되지 않는다.
-atomic값으로만 구성된 model을 flat relational model이라하거나
-First Normal Form 가정을 만족한다고 한다
composite, multivalued한 값을 갖는 relation은 Non first normal form (NF 2) or nested relations 라고 불린다.
NULL값은 해당되지 않거나 모르는것에 대해 표시를 할수 있으며 atomic value로 간주한다.
Relational Model Constraints
유효한 relation instances들이 반드시 지켜야할 제약 조건을 이야기한다
3가지 종류 :
- 모델 고유의 제약조건 => 내포적인 제약 (당연한것들 ex) 튜플엔 순서가없고 중복이없다)
- 스키마에 따른 제약조건 => 외재적 제약 ( data모델의 스키마를 정의하면서 표현되는것들)
- 응용에 따른 제약조건 => semantic constraints or business rules, 응용 프로그램에 적용되면서 표헌되는것들 ex) 수강신청을 할때 생기는 제약들
Schema-based Constraints
-key constraints
-Constraints on NULLs
-entitiy 조항의 경우 => 개체 무결성 제약조건
-referential의 경우 => 참조 무결성 제약조건
추가 제약조건
-domain 제약 -> attributes 타입에 관한 제약조건
-data dependencies => 정규화할때 사용되는 일종의 규칙
Domain Constraints
-attribute의 값에 대한 제약조건, 그 attribute가 정의된 도메인에서 나온 atomic value여야한다.
-sql이 제공하는 data types을 갖게된다
-그 값의 범위를 정해줄수 있다
-값의 list를 주고 한가지를 갖는 제약조건을 줄수 있다.
Key Constraints
relation은 튜플들의 집합 -> 즉 튜플들은 서로 구별되야함 구별해주는 attribute가 식별자고 그것이 key다
R안의 Superkey는 attribute의 집합이며 서로다른 튜플 t1 ,t2가 있을때 그 모든 임의의 튜플 t1,t2의 attribute의 값은 같지 않고
이것을 만족하는 attribute의 집합 SK를 superkey라 하며 유일성 제약조건(uniqueness constraint)를 표시하는 의미를 나타낸다.
Key of R : A "minimal" superkey
Relation의 key는 minimal한 superkey로 나타낼수있다. Relation에서 임의의 서로다른 두 튜플을 꺼냈을때, 그 튜플에 있는
Key attriubtes 값은 서로 달라야한다. ( Superkey의 정의)
그리고 minimal superkey여야한다. unique하기 위해서 필요한 attribute들만으로 구성되어야 하며 어느 한가지라도 제거할시
unique조건을 만족하지 못하는 superkey를 말한다. unique와 minimal한 성질을 가진다면 Key라고 할수 있다.

Candidate key
Minimal하고 unique한 조건을 만족하면 모두 Candidate key가 될 수 있다.
그 중 선택된 main key를 primary key라고 한다. ( 대표가 되는 기본키)
PK의 선택시 한개의 attribute로 될 수 없더라면 가장 적은 개수를 갖는것이 좋다.

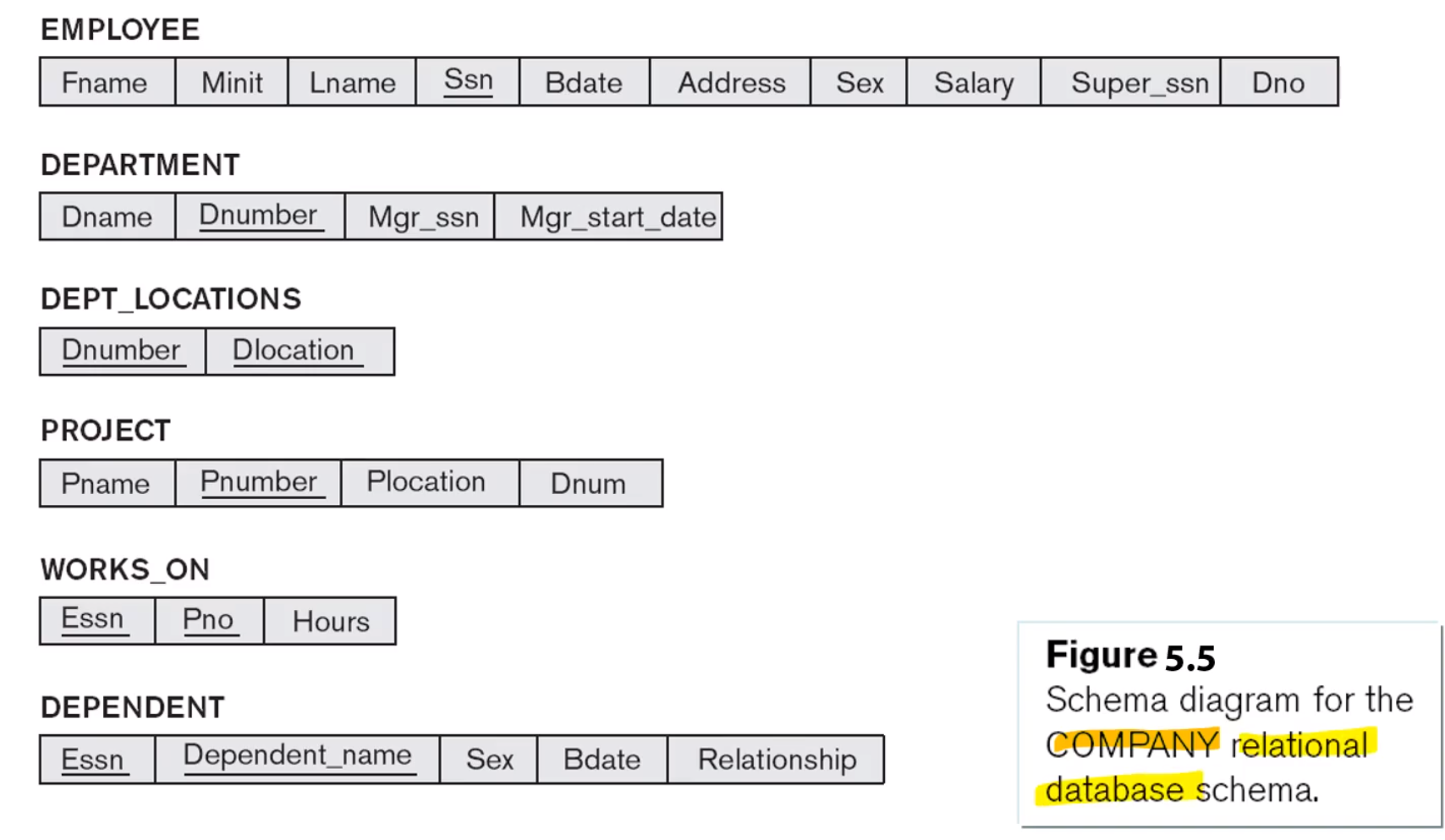
Relational DBs and Relational DB Schemas
-A relational database schema S
relational database schema는 relation schemas들의 집합이며 거기에 관련된 무결성 제약조건들이 같이 들어 있다.
-A relational database state DB of S
relatioal database state는 해당되는 schema를 갖는 states들의 집합이다

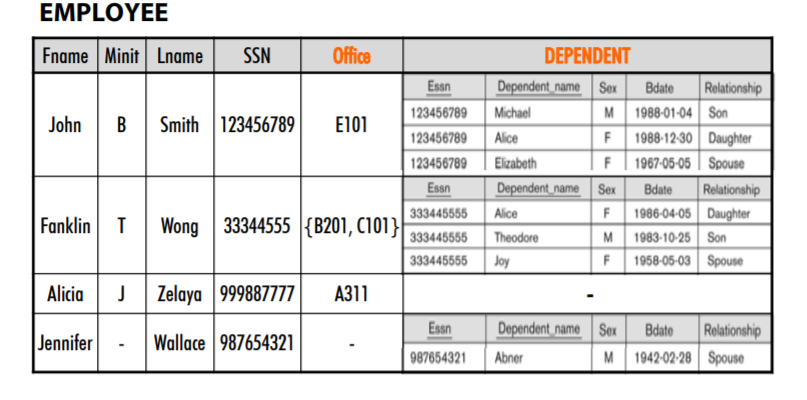
-Attributes는 동일한 real-world의 개념을 표시하지만 서로 다른 이름을 가질 수 있다.
이름이 달라도 둘은 동일한 정보를 가짐
-반대로, 서로 다른 정보를 동일한 attribute 이름으로 표시할 수 도 있다. ( 예시처럼 구분안짓고 Name으로 명명한경우)
Entity Integrity 개체 무결성
pk(primary key)값은 언제 어떤 튜플에서라도 절대로 NULL값을 가지면 안되는 제약 조건
pk는 튜플을 다른 튜플과 구분해주는 값인데 그것이 없다는것은 Relation간의 식별이 불가능하기 때문에 기존 조건에 위배된다.
또한 Pk가 아니여도 특정 attribute에 대해 null값을 허용하지 않는 경우가 있는데 그때는 별도의 제약조건으로 표시할수 있다.
Referential Integrity 참조 무결성
두 relation관에 관련성이 존재할때 어떤 relation의 튜플이 다른 relation의 튜플을 참조할 수 있다.
참조하는 것을 referencing 당하는것을 referenced ( R1이 R2의 PK를 갖고 있어서 그 PK를 통해 R2를 찾아갈 수 있다.)
참조하는 relation R1 의 참조 당하는 relation 즉 R2의 PK를 FK(foreign key) 라고 부른다.
t1[FK] = t2[PK]
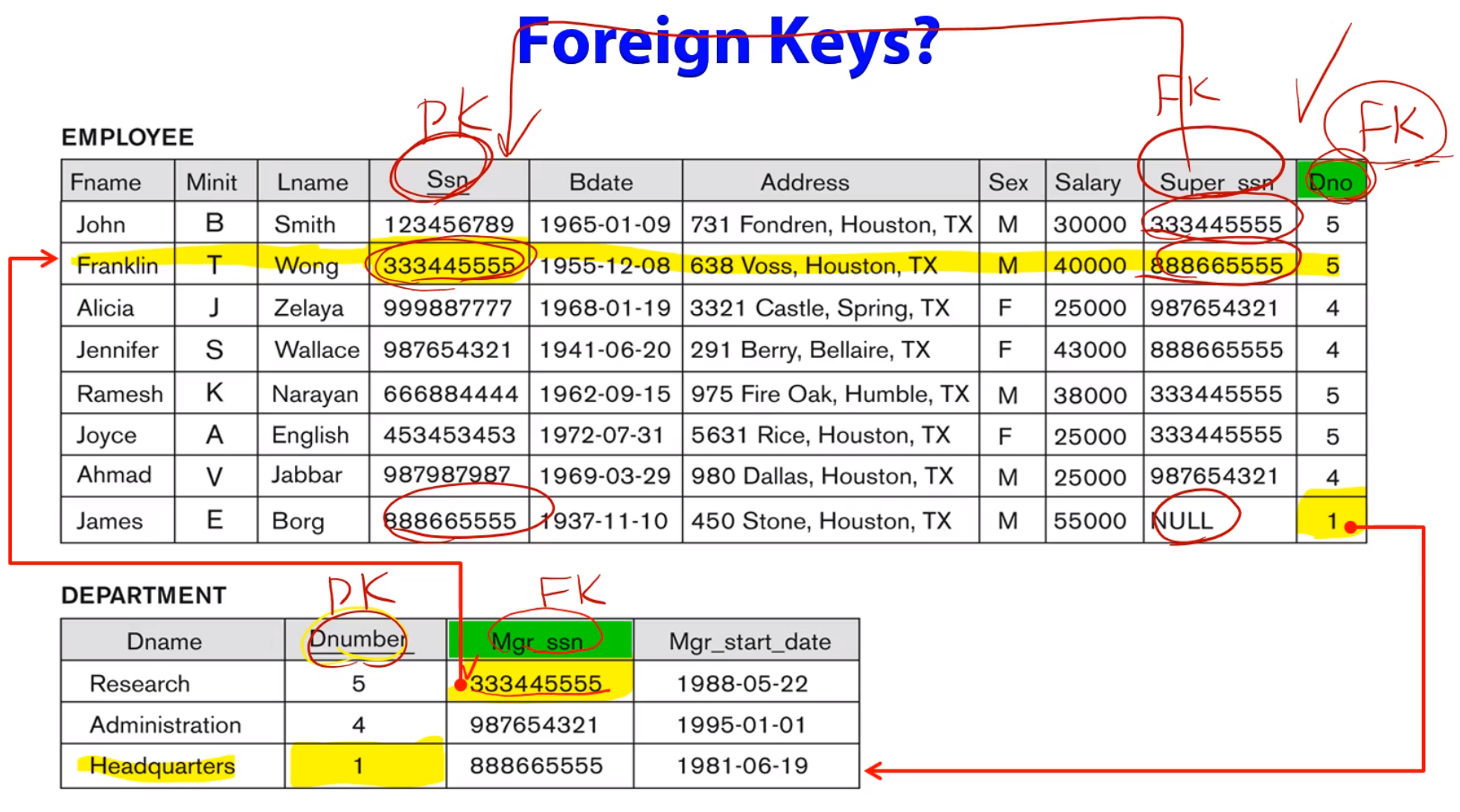
R1에 있는 attribute의 집합 FK가 relation R2를 참조하고 있는 R1의 FK라고 가정하면 다음 두가지 규칙을 만족해야한다.
- FK안의 attribute는 R2의 PK와 같은 domain을 가져야한다.
-R1이 R2를 참조하고 있을경우 R1의 한 state에 있는 튜플 t1의 FK값은 R2의 현재 state에 있는 어떤 튜플 t2의 PK값과 같아야하거나
(R1의 tuple t1이 R2의 tuple t2를 참조한다는 의미) null값을 가져야한다(참조하는 relation이 없다)

Update Operations and Dealing with Constraint Violations
relation연산 검색, 갱신 두부류. 검색의 경우에는 제약조건에 걸리지 않아서 괜찮으나
갱신의 경우 3가지 방식의 연산( 삽입 , 삭제 , 수정) 이 제약조건을 위배하는 경우를 만들어낸다.
DBMS는 무결성이 위배되는 경우, 4가지 행동대처를 한다.
- 연산 거부 ( 기본 key값을 NULL로 만들려는 행동같은 것)
- 연산은 허용하나 사용자에게 제약조건 위배를 알려준다(가벼운 에러)
- 자동으로 교정하는 방법(R1이 R2를 참조할때 참조한 R2값이 제거되는 경우 R1의 FK값이 위배된다 그때 DBMS가 두 방법으로 자동해결해줌)
Cascade option = R1도 그냥 같이 지워버리는 방법
SET NULL option = R1의 FK값을 NULL로 바꿔버리는 방법
- 어떤 error가 생겼을시 사용자가 조치를 취하도록 action을 만든다
'Database' 카테고리의 다른 글
| Database 8장 (0) | 2020.10.10 |
|---|---|
| Database 7장-2 (0) | 2020.10.02 |
| DATABASE 7장 (0) | 2020.09.26 |
| Database 6장-2 (0) | 2020.09.19 |
| Database 6장-1 (0) | 2020.09.11 |



