
좋은 relation schemas
논리적 레벨 : relation에 있는 데이터의 의미를 얼마나 잘 표현하느냐
구현 레벨 : base relation의 schema가 얼마나 잘 구성되 있느냐

관계 스키마를 위한 비정형적 품질 측정 기준
1. attribute의 semantics를 schema가 얼마나 명확하게 표현하고 있느냐
2. 튜플의 중복값을 얼마나 감소시킬수 있느냐
3. null값을 줄여야 한다
4. 불필요한 튜플을 만들 가능성을 허용해서는 안된다.

가이드라인1
-관계 스키마를 설계시 의미를 쉽게 설명할 수 있어야 한다
-하나의 개체, 관계성 타입은 하나의 realtion schema에 표현해야 한다.(막 섞으면 안됨!)




가이드라인 2 (중복에 관해 생기는 문제)
-삽입,삭제,수정에 관한 이상이 생겨선 안된다
-만약 이상을 피할수 없다면, db가 명확히 작동할 수 있도록 해주어야 한다
이러한 가이드 라인은 특정 질의 성능향상을 위해 때로는 위반될 수 있다.
-직원과 부서의 정보를 자주 검색해야할때, EMP_DEPT가 필요할 수 있다.
이럴땐 이상이 생기지 않도록 매우 신중히 처리해야함

스키마 설계의 중요한 목적중 하나는 base relation이 차지하는 기억공간을 최소화 하는것
-여러 relation을 하나의 shecma에 표현시 많은 중복문제 발생
하지만 이것보다 더 큰 문제를 일으키는건 갱신연산
-삽입 이상
-삭제 이상
-수정 이상




가이드라인3
-base relation에 null값을 빈번히 갖는 값을 위치시키지 말것
-null을 피할수 없을경우,특별한 예외의 경우에만 적용될 수 있게 구성해야 한다.

튜플 내부의 NULL 값
fat relation(많은 속성을 갖는 relation ) -> 많은 null값을 생성하는 경우가 있다
-공간 낭비
-attriubte의미가 불분명, join연산 하기 힘들다
-집단연산 수행시 곤란한 부분이 생김
-null값 자체에 대한 여러 해석이 가능

가이드라인 4
-relation schemas 설계시 Join 연산이 반드시 Pk와 Fk사이에 동등조건으로 실행될 수 있게 해야한다.
-Nonadditive join property(쓸데 없는것이 들어가지 않음)
relation이 pk, fk 결합외에 다른 속성간에 join을 이루어질 수 없게 만드는게 좋다.



Functional dependencies(함수적 종속성)
-relational model의 가장 중요한 제약종류
-함수적 종속성은 이상이나 데이터 중복성을 제거하기 위해 db를 재설계 하는것에 있어 가장 중요한 지식

함수적 종속성 정의
relation shcema의 한 state에서 조건을 만족하면 된다.
R에 있는 임의의 두 튜플에서 X attribute값이 같다면 Y attribute값도 같아야 한다.
-X의 값은 Y의 값을 특별하게(함수적으로) 결정해준다
-어떤 튜플의 Y의 값은, X의 값에 의존하며 X값에 의해 결정되며 함수적으로 종속 되어있다.
FD:X-> Y
-X: 결정자
-Y: 종속자
함수적 종속성은 attribute의 의미를 표시하는 성질이다.



함수적 종속성은 relation shcema에 관한 조건, 특정 인스턴스에 대한것은 아니다
-스키마만 보고 종속성이 있다고 판단할수 없다
-FD는 attribute의 의미에 관련된 성질
-모든 데이터가 따라야 하는 제약조건
Relation extension 이 있을때 FD를 만족해야만 그 상태를 합법적인 extensions이라 한다.


Pk기반 정규형
relation에 대해 pk와 FD가 주어지면, 4가지 form을 결정할 수 있다.
4정규형은 multivalued dependency에 의해 결정
5정규형은 join dependency에 의해 결정

관계 정규화
normalization : 테스트를 통해 relation이 정해진 normal form을 지키는지 확인하는 과정
-FD와 PK를 기반으로 분석하여 , 중복성을 최소화, 삽입,삭제,갱신 이상을 최소화
-만족되지 않는 relation schema에 대해서는 조건을 만족하면서 더 작은 relation schema로 분해
-분해를 통한 normalization과정에서 만족해야 하는 두가지 성질 : 중복성 최소화, 삽입,삭제,갱신 이상 최소화

-Lossless join
분해된 relation을 다시 원래relation으로 만들때 잉여 튜플을 만들면 안된다
-Dependency preservation propery
원래 relation에 있던 종속성을 분해된 후에도 가져야한다.
비정규화
-relation을 작게 분해하면 그것을 다시 join을 해야하는 문제가 생긴다.( 비싼 연산)
성능에 큰 영향을 주기 때문에 정규형의 반대로 가게 될때 생기는 현상

-K가 candidate key가 되기 위한 조건
1. K가 R의 모든 attribute를 함수적으로 결정할때.
Attribute K의 값이 주어질때 동일한 튜플은 존재할 수 없다. K=> superkey 만족
2.K의 어떤 부분집합도 나머지 attribute를 함수적으로 결정해선 안된다. K=> minimal 만족



Non-1NF를 1NF로 변경하는법





완전함수종속
X가 attribute의 집합인 경우 X의 어떤 부분집합도 Y를 결정하지 못할때
X의 어떤 부분 집합으로 Y를 결정할 수 있다면, 부분 함수 종속이라고 한다.
예시 1 FFD, PFD



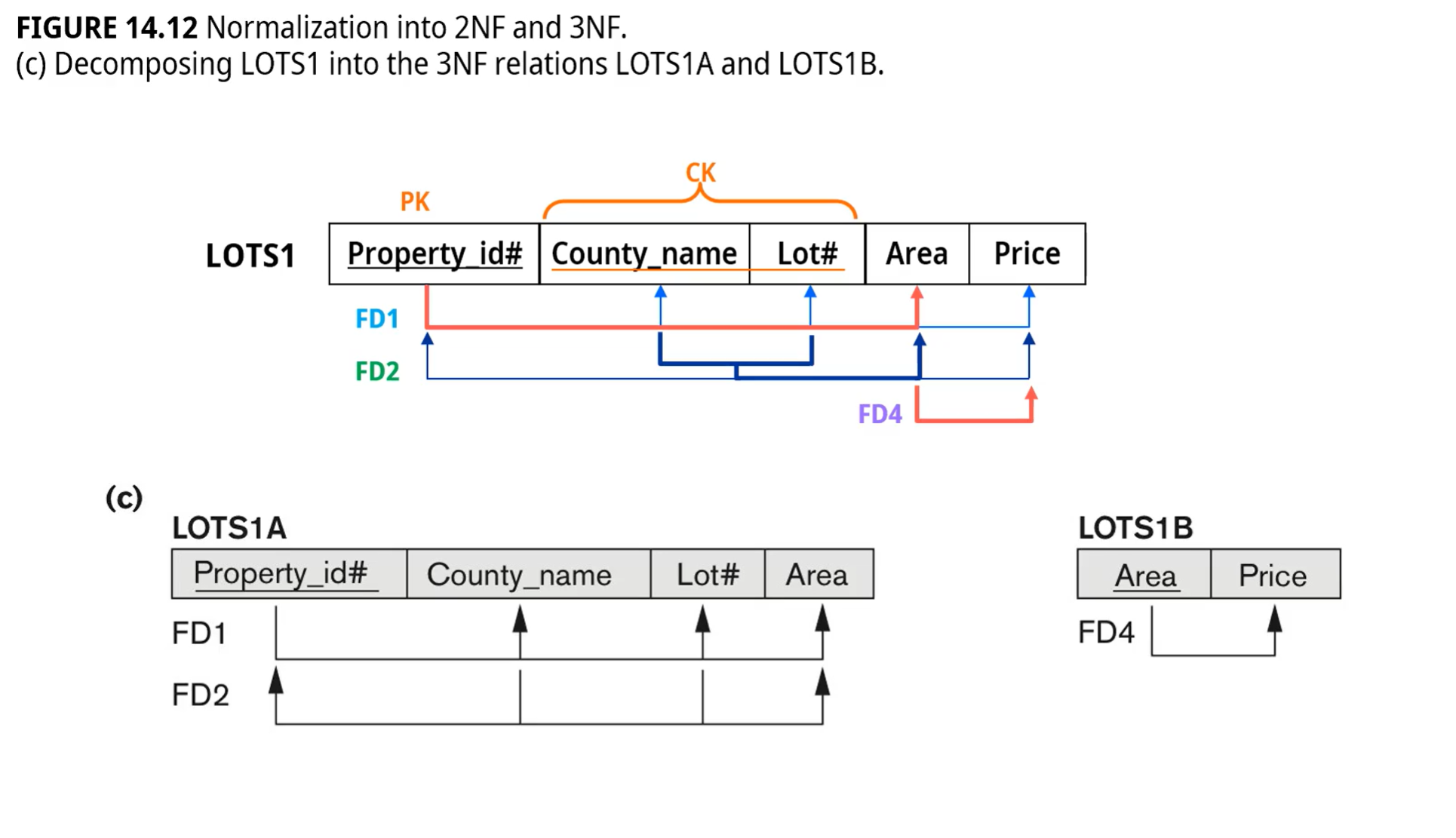
이행적 종속성
x가 Y를 결정할때 중간에 Z가 있고, X가 Z를 결정 후 Z가 Y를 결정하면 X는 Y를 결정한다
(Z가 ck나 key의 부분집합이 아닐때)
ssn -> Dname -> D ssn






일반적 정의의 3NF
모든 nontirivial FD X->A가 있을때 X가 R의 superkey거나 A가 R의 prime attribute이다.
R의 모든 nonprime attribute는
R의 모든 key에 ffd여야하고 비이행적 종속성을 가져야 한다.







4NF의 정의
다치 종속이 성립하면 데이터 중복이 되기 때문에 여러개의 튜플을 지우고 싶어도 여러개 지워야 하고 삽입을 하려고 해도 여러개의 삽입을 해야한다 그래서 제 4 정규형을 정의한다.
table에 다치 종속이 존재하지 않으면 그 relation을 제 4 정규형이라고 한다




원래 relation을 n개로 projection한후 natural join을 해야만 join dependency
MVD는 join dependency의 특수한 경우이다.(n=2)
(JD>MVD>FD 포함관계 )


어떤것을 join을 하던 원래 relation이 나오지 않음.
원래의 relation을 만들기 위해서는 어느 두개를 Join한 후에 나머지와 또 join을 해야만 원래 relation을 만들 수 있다
SUPPLY relation은 R1, R2, R3가 슈퍼키로 구성되어 있지 않고 슈퍼키의 일부로 구성되어 있으므로 MVD는 존재하지 않으므로 4NF은 될 수 있지만 5NF는 될 수 없다.
차수가 binary인 정규형은 무조건 제 5 정규형이 된다.
'Database' 카테고리의 다른 글
| Database-16장 (0) | 2020.10.22 |
|---|---|
| Database - 10장 (0) | 2020.10.22 |
| DATABASE 3장 (0) | 2020.10.10 |
| Database 8장 (0) | 2020.10.10 |
| Database 7장-2 (0) | 2020.10.02 |



