

계층 구조
-주기억장치
CPU가 직접 조작할 수 있는 저장 장치 (main 메모리, cache 메모리 존재)
-2차 보조기억장치
속도는 느리나, 대용량을 저장할 수 있다
-3차 보조기억장치
offline상태에 있다가 user가 직접 access해주어야 하는 저장 장치 (CD)


-물리적 db 디자인
다양한 저장 option중에서 가장 효율적인 저장기법을 선택하는 것
-필요한 레코드를 가장 효율적으로 찾아낼 수 있는 저장 방식

파일구성 방식 (primary , secondary)
실제 디스크상에서 record를 물리적으로 저장하는 방법을 결정한다
주 조직 방법에 따라 record가 저장되고, 저장 방법에 따라 record를 access하는 법도 같이 결정된다
-heap file : record들이 disk에 첨가된 순서대로 저장된 방식
-sorted file : 정해진 field 값에 따라 record가 정렬되서 저장되는 방식
-hashed file : hash key를 이용한 hash function으로 저장 위치가 결정되는 방식
B tree같은 tree구조를 이용한 방식도 존재한다

secondary file organizations
보조 access structure을 제공하는 방식
-primary에서 사용되는 field가 아닌 다른 field에 대해 사용되는 것을 이용해 file에 효율적으로 access가능하게 한다
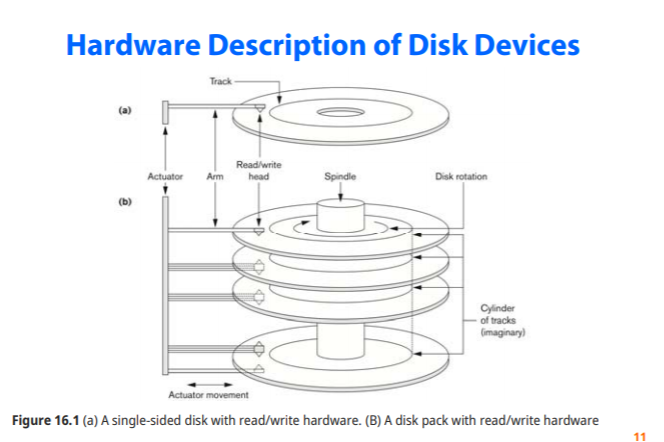
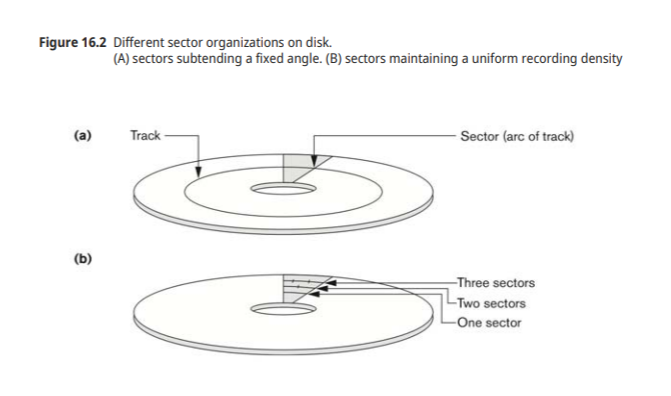

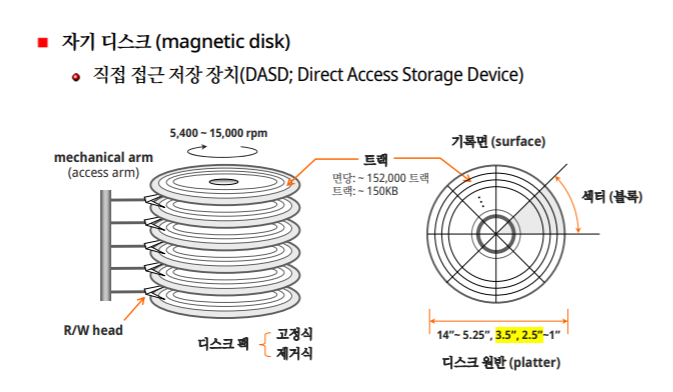
자기 디스크
-직접 접근 저장 장치 : 특정 위치를 바로 갈 수 있다.
용량을 높이기 위해 대부분은 고정식을 사용한다

트랙과 실린더
트랙 하나마다 한개의 실린더가 생긴다.
같은 실린더 내부에 존재하는 data를 읽기 위해서는 head가 움직이지 않아도 되기 때문에
한 실린더에 연속적으로 데이터를 기록한다. 용량이 다 찰시 다음 실린더로 이동한다.

디스크블럭(page)
-os가 디스크 formatting이나 initialization 하는 과정에서 동일한 크기의 트랙을 나눠놓은 영역
보통 0.5~8kb 용량 갖음
하드 코딩된 sector를 갖는 디스크에서는 이런 sector를 나누거나 결합하여 block으로 만든다.
-디스크에서 main memory로 불러오는 최소단위
블럭은 다음 블럭을 읽어올지에 대한 control information을 저장하고 있는 interblock gaps이 존재한다.

디스크 주소법
디스크 블럭
-random access가 가능한 주소가 부여된 장치
-main memory와 disk사이의 전송단위
block의 하드웨어 주소를 주는법
1. 실린더 번호,트랙 번호, 블럭 번호
2. Lba : 맨 첫번째 블럭부터 번호를 주고 상대번호로 data를 찾는방법


:

디스크 주소
Buffer : 디스크를 블럭단위로 입출력을 하므로 메모리에 위치시켜야한다, read, write buffer
cluster : 몇개의 블럭들을 묶어서 cluster단위로 주소를 부여하고, cluster단위로 데이터를 입출력한다.
buffer 사이즈는 cluster단위에 맞춰 조절해 주어야 한다
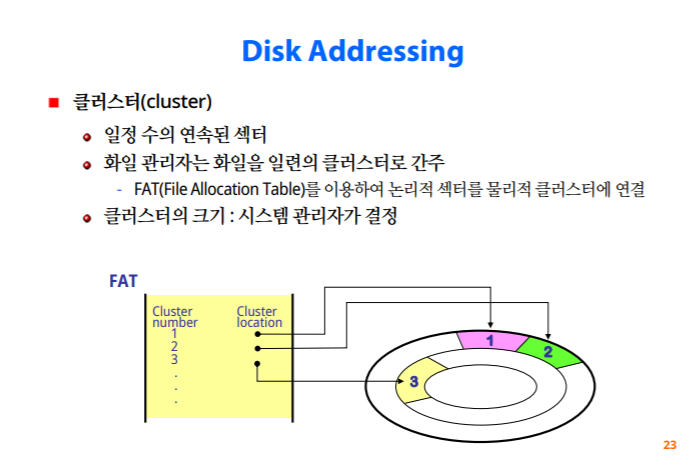
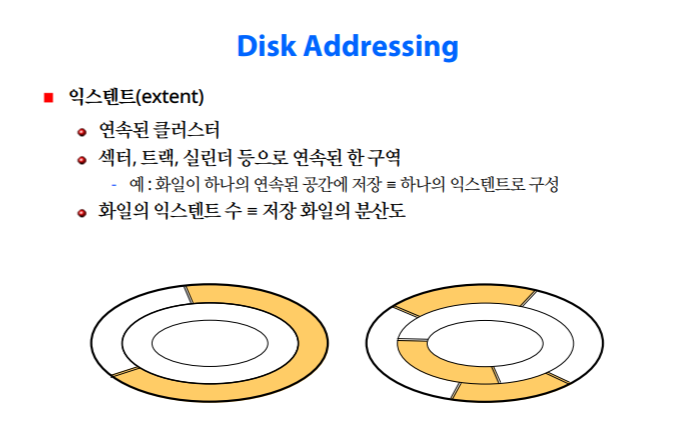
익스텐트
하나의 익스텐트로 구성 되있는경우, 세개의 익스텐트로 구성되있는 경우
조각 모음: 흩어져 있는 file을 묶어서 연속된 하나의 덩어리로 만들어주는 작업


데이터 전송 연산
탐구 : 헤드가 안으로 들어가는 과정
탐구시간 : 들어가는 소요 시간
head activation : 특정면 헤드의 활동 시간 (0에 가깝다)
회전 지연 시간(rotational delay, latency) : 해당 블럭이 시작점 부터 head 밑까지 오는 시간
data transfer ( block transfer time, btt) : 블럭이 헤드 밑을 지나가는 시간

맨 바깥에서 맨 안까지 걸리는 시간의 1/3을 탐구시간으로 하는 경우가 많다
회전 지연 시간 : 보통 반바퀴로 결정
fixed head disk, movable head disk 두가지 존재, 대부분 후자를 이용한다.

bulk transfer(대량 전송)
하나의 트랙 또는 실린더에 연속되어서 저장되어 있는 여러개의 블럭들을 읽어 들이는것
평균 디스크 블럭 읽는 시간: 9~60
연속블럭 : 첫 블럭 제외 나머지는 0.4~2 밖에 걸리지 않는다
디스크에서 제일 중요한 것은 연속된 검색이 가능하도록 블럭들을 위치시키는 것이다

디스크에서 좀 더 효율적인 데이터 접근
-버퍼링을 통해 cpu와 hdd 사이에 속도차이를 보완
-디스크의 데이터 구조를 적절히 설계함으로써 관련 데이터를 연속된 블럭에 위치하도록 함
-탐구시간 최소화를 위해 한 블럭을 버퍼에 읽어 들이면 나머지 트랙도 같이 읽어들이게 함(랜덤블럭을 읽을땐 의미없다)
-전체 access time이 최소화 되도록 disk를 한방향으로 이동할 수 있게 한다.
-기록을 임시로 저장할 log disk나 log file을 사용, seek 타임 감소
-recovery를 위해 ssd나 flash memory를 사용

SSD 저장소
flash memory - main memory와 hdd사이의 중간 층
-ssd or ssds
-대형 시스템용 flash drive는 EFD라고 부름
ssd는 controller와 서로 연결된 flash memory card로 구성되있다.
기준 form factors: mSATA , M.2
interface : SATA express

HDD:
-관련된 데이터가 연속적으로 저장되어야 한다
-update 될시 해당되는 블럭에 overwrite를 해준다
SDD:
-반도체 메모리기 때문에 어느 위치를 access하건 같은 시간이 걸린다
(흩어져 있어도 단편화 문제가 발생하지 않는다)
-NAND cells은 읽고 쓸 수 있는 횟수가 정해져 있기 때문에 wear-leveling방식을 쓴다.
(overwrite 하지 않고 새로 data를 입력, 그래서 용량이 hdd보다 상대적으로 큼)

Magnetic Tape storage device
magnetic tapes : disk와 다르게 sequential access 형태를 가진다.
-n번째 블록을 읽으려면 , n-1개 블럭을 다 지나야한다
-기억 공간 활용을 위해, Blocking(여러개의 block을 하나의 record에 묶는 작업) 방식 이용
-백업용으로 주로 사용된다
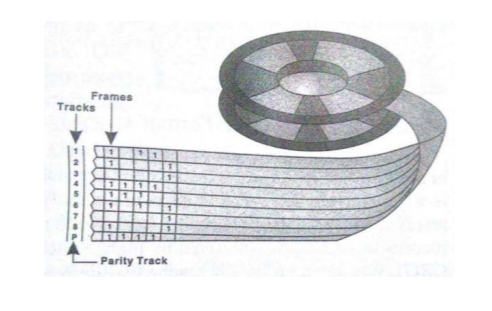


IBG
disk의 gap : 다음 블럭을 읽을지 말지
tape의 gap : IBG, IRG
data를 읽고 감속,가속 구간이 존재하는데 이 시간 동안은 아무것도 할 수 없는 시간이 된다.
Record를 최대한 길게하여 이 구간을 줄이는것이 중요하다.

CD-ROM : 레이저 반사여부에 따라 0,1 을 표시 , 안에서 부터 연결된 구조
CLV : CD-ROM은 안에 읽는것을 읽을땐 빨리, 밖에 있는것은 느리게 읽는다 선형 장치이기 때문에 jump가 안되고 빙글빙글 돌아서 가야한다
CAV : disk방식 , 같은 각도는 같은 용량을 가짐
'Database' 카테고리의 다른 글
| Database-17장 (0) | 2020.11.15 |
|---|---|
| Database-16 (0) | 2020.11.05 |
| Database - 10장 (0) | 2020.10.22 |
| Database 14장 (0) | 2020.10.22 |
| DATABASE 3장 (0) | 2020.10.10 |



