
Buffering of blocks
-미리 사용할 블록 주소를 다 알고있다면, 지연없이 빠르게 처리하는것이 가능하다
-한 버퍼를 읽거나 쓰고 있을때, CPU가 다른 버퍼를 채울 수 있다.
-별도의 disk I/O 프로세서가 위의 작업을 담당한다
동시수행의 두가지 경우
왼쪽 A,B가 교대로 수행, interleaved concurrency
오른쪽 C,D가 동시에 수행
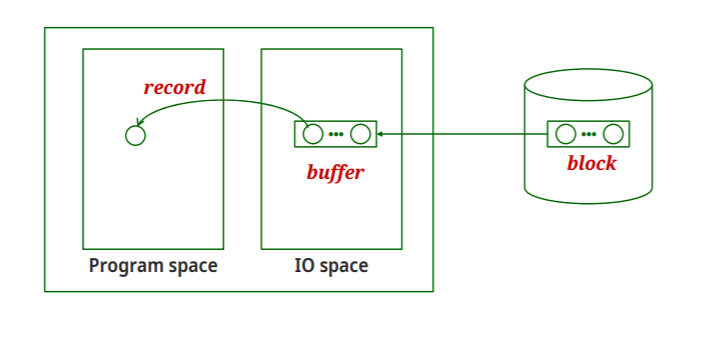


Buffer manager-DBMS의 Software component
1.Main memory에서 요청된 페이지가 발견될 확률을 최대가 되도록 해준다
2.기존에 있던 page를 대체할 수 있는 공간을 찾아야한다.
buffer pool : buffer가 쓸수가 있는 공간을 미리 할당해놓는 곳
교환을 위해 필요한 정보의 타입
-pin count
현재 해당되는 buffer를 몇개의 process가 쓰고 있는지 계산해준다
pin-count=0 => unpinned(아무도 쓰고있지 않음)
-dirty bit프로그램이 업데이트가 되면 dirty bit가 1이고, 되지 않는다면 버린다

Buffer replacement Strategies
-LRU 알고리즘
-Clock policy ( 교대로)
-선입선출 알고리즘
-MRU(가장 최근에 쓰인것을 먼저)

Records and Record Types
Database 내의 data들은 File속에 record 형태로 저장되어 있다.
-record를 disk속에 어떻게 저장시킬지 기법을 고려해야 한다

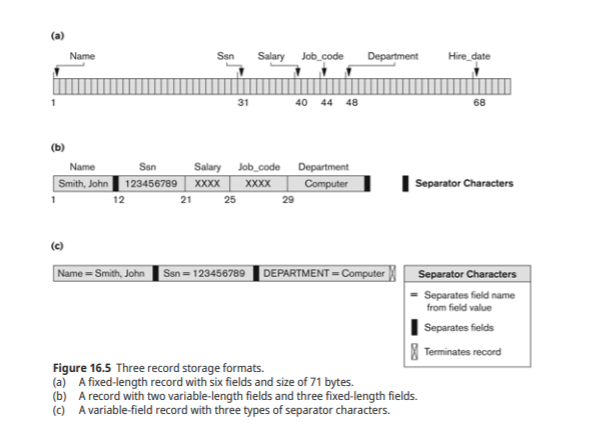
Fixed-length record(고정길이)
Variable length record(가변길이)-record길이가 가변
-가변길이 field
-repeating field
-optional field
-mixed file

Record Blocking and Spanned(신장) vs Unspanned(비신장) Records
-disk block = 데이터 전송 단위
Bfr = B/R
-가변길이의 경우
bfr= records의 평균 number를 지정
-파일의 r records의 필요 블락수
b=r/bfr blocks


Unspanned : record를 저장을 하다가 공간이 부족하면, 공간을 버리고 다음번에 record를 저장 (공간낭비)
spanned : 저장할 수 있는데까지 저장한후 나머지를 다음 블럭에 저장, record를 둘로 쪼개고 pointer로 연결해준다 (Block2개 이용)
대부분의 경우 Unspanned를 사용한다

File에 Block 할당
-연속할당 : file block을 연속되게 저장하는 방법 (file reading이 빠름/ file확장이 어려움)
-Linkedlist로 연결 (느리다/ 확장이 쉽다)
Combination : 두가지 방식을 합침, 가능한 최대한 연속된 block의 cluster를 할당을 해주고 cluster를 linkedlist로 연결한다.
Indexed allocation : index 블럭이 각자의 file block에 대한 pointer를 가진다 (FAT와 동일한 방식)

File Headers
-파일에 대한 control 정보 블럭, file header or file descriptor
file block의 디스크주소 결정, record format 정보
가장 좋은 file 구조 : 원하는 record를 찾을때 block transfer를 최소화 시킨다


File 연산
-검색연산
-갱신연산
미리 고치고자 하는 record를 찾기위한 검색이나,filtering이 제공되야한다.
-open,close
-Record-at-atime operations : Reset,find,Read,Findnext,Delete,Modify,Insert (한번에 한 record씩 처리)
-scan : find,FindNext,Read 연산을 연손적으로 한번의 계산으로 처리
-Set-at-a-time : FindAll, Find n, FindOrdered, Reorganize

File Organization and Access Method
-File organization
파일 속의 데이터에 record,block,접근 구조를 말한다
이런 record와 block들을 저장 장치에 위치시키는 방법을 포함한다
Access method : file organization방법에 따라 원하는 특정 record나 block을 검색하기 위한 방법
-file에 적용 될 수 있는 group이나 operation을 제공
-file 조직방법에 따라 여러 접근이 제공됨
-특정 file 조직 방법에만 쓸 수 있는 access method도 있다.

EMPLOYEE file 예시 1
-삽입,삭제,갱신연산 수행
-특정 record를 삭제나 수정하기 위해선 그 record를 식별하기 위한 선택 조건이 필요
-Ssn을 베이스로 적용한다
가장 좋은 file 조직 방법은 Ssn값을 이용해 빠르게 찾으면 된다
-Ssn value로 index를 정의하거나 sorting한다

EMPLOYEE file 예시 2
직원들의 급여 체크를 하되 부서별로 그룹화 한다
-가능하면 동일한 부서에 있는 직원들이 연속적으로 저장되는것이 좋다


Heap or Pile File
Record가 삽입된 순서대로 저장이 되는 방법
-새로운 record는 file 끝에 첨부가 된다
-특별한 조직없이 record 수집 목적으로 사용된다
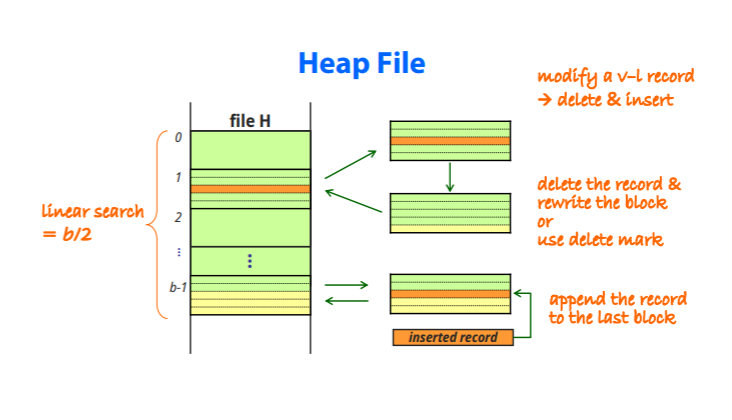
삽입 : RECORD의 마지막에 저장해야하므로 파일의 마지막부분을 가져와서(Main memory) 기록하고 다시 집어넣는다
수정 : 수정목록을 메모리로 가져온뒤 record를 빼고 rewrite하거나 delete mark를 한다.
비어있는 공간은 사용하지 못하며, 수정된 record는 insert와 같이 record의 마지막에 삽입된다.
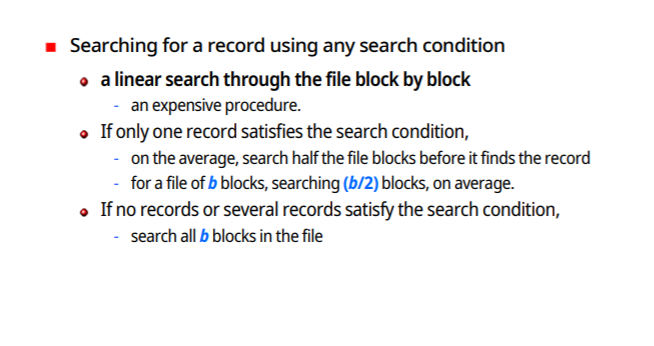
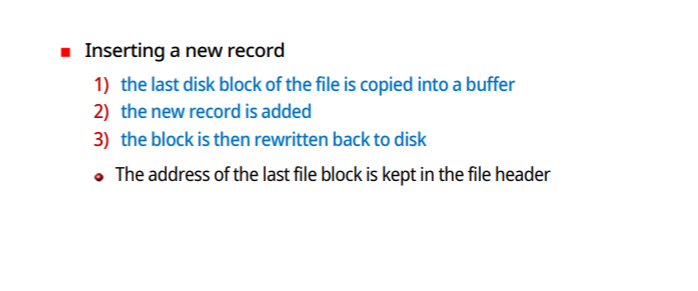
새로운 record 삽입
-마지막 block을 buffer로 가져옴
-buffer에 insert할 record 첨가
-그 block을 다시 file에 기록한다

record 제거
-지울 block을 찾음
-block을 buffer에 복사
-해당 record를 buffer에서 제거
-나머지 내용 disk에 rewrite (빈 공간은 낭비되는 공간이 된다)
경우에 따라선 delete mark만 붙혀놓고 rewrite하는 경우도 있다.
낭비되는 공간때문에 주기적으로 재구성하는 작업이 필요하다.

가변길이 record의 수정
-기존 record를 지우고 새로운 record를 삽입한다
-수정된 record가 예전 공간에 맞지 않을 수 있기 때문이다
특정 field값에 따라 순서대로 record를 읽어내는 경우
-external sorting을 통해 일시적으로 만들어내서 읽어낸다
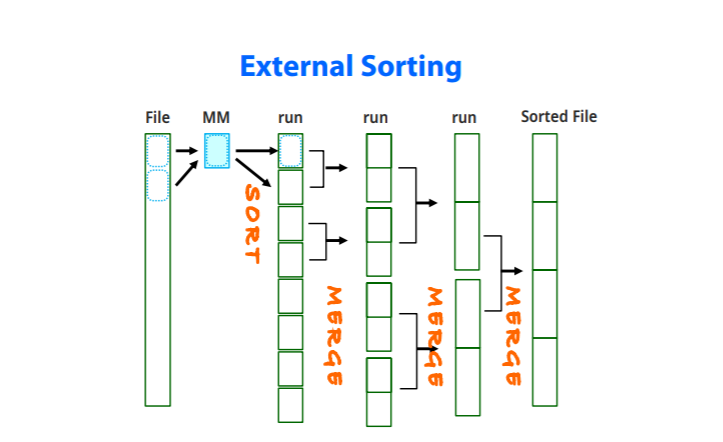
External sorting(Main memory에 데이터가 다 들어가지 않을때 쓰는 방법) : file을 이용한 sorting
-file에서 Main memory로 데이터를 가져온다
-MM에서 sort한 뒤 run이라는 sorted subfile을 만든다 ( 생성되는 갯수는 File크기에 비례한 MM의 배수)
-run들을 병합해 나가서 Sorted file을 생성한다
-많은 I/O처리와 필요공간 때문에 부담이 가는 연산이다
internal sorting : Main memory에 모든 데이터를 올려놓고 한꺼번에 sorting

Relative or Direct File
-File의 record를 주소로 찾는게 아니라, 상대번호를 준다
-번호를 지정해 주었기 때문에 해당되는 record가 몇번에 있는지 금방 찾을 수 있다
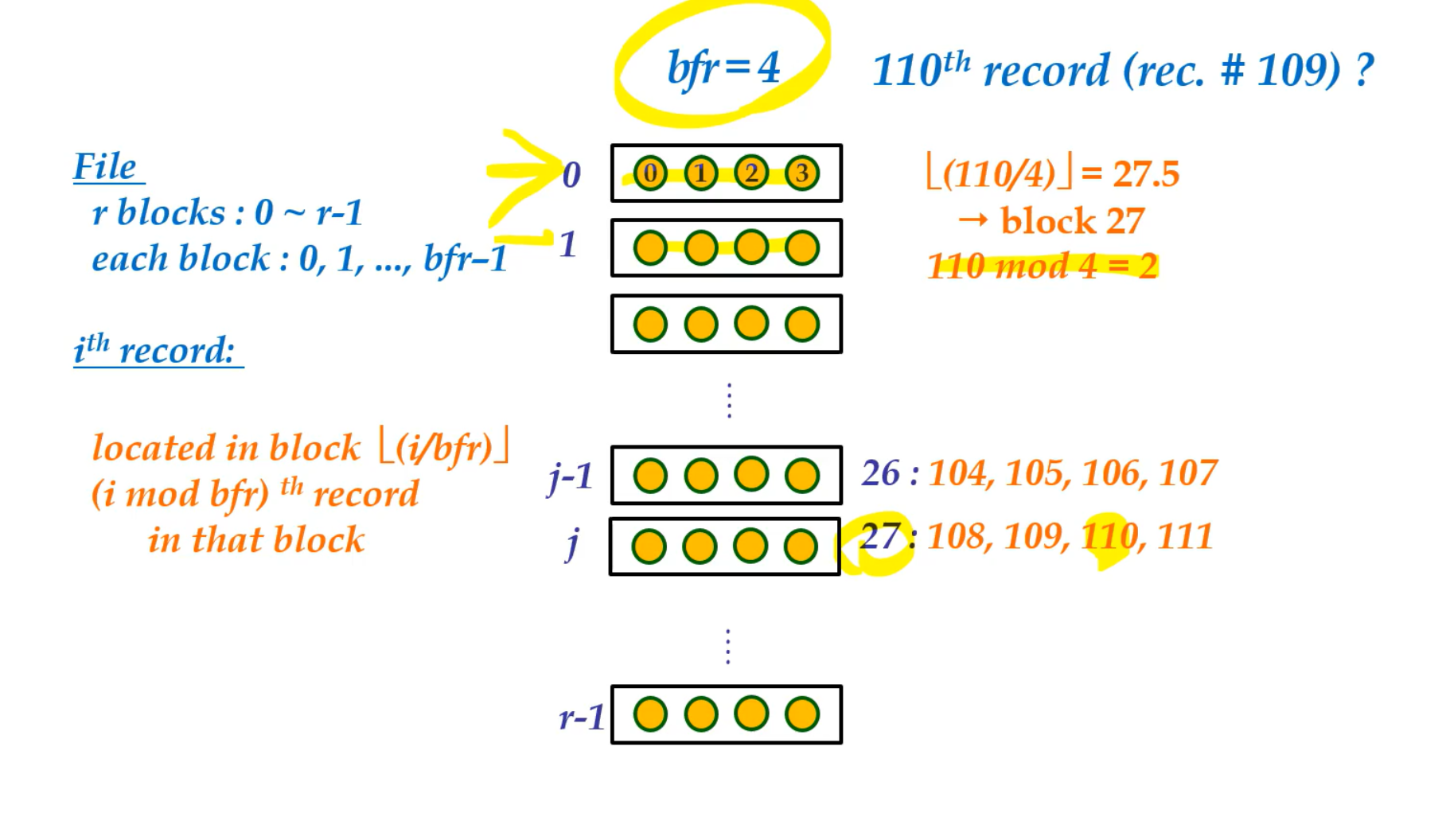

Ordered or Sequential Files
특정 field의 값에따라 정렬이 되있는것을 말한다
정렬된 field가 key라면 ordering key라고 한다.
key field : 각 record내의 unique value

정렬 file들에 대한 장점
-record를 차례대로 읽기 편하다
-buffer내에 이미 들어왔기 때문에 첫 index만 접근하면 나머지에 대해선 할 필요가 없다
-binary search를 이용하면 log시간내에 가능
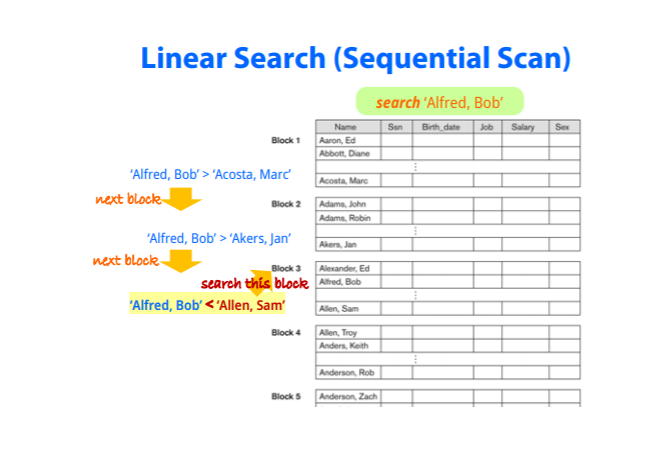


Searching in Ordered Files
-부등호에 대해 꽤 효율적인 탐색성능을 보인다
-random access나 정렬키가 아닌것으로 검색한다면 순차적인것이 아무 의미가 없어진다
(이런 경우 Linear search보단 sort된 임시적 file을 이용해 찾는경우가 나을때가 있다)

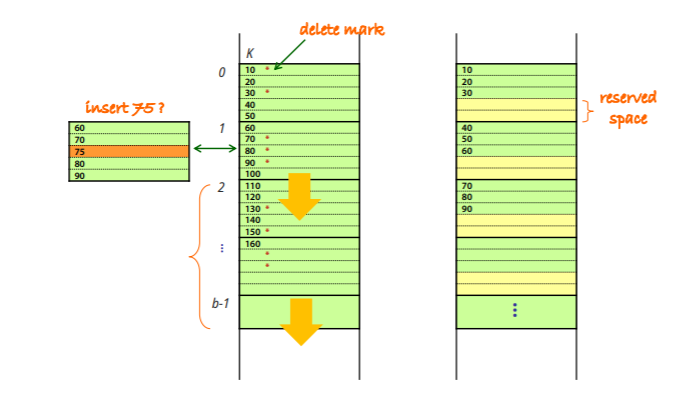
Insertion and Deletion in Ordered Files
-기본적으로 정렬되있기 때문에 두 연산이 매우 비싼 연산이다
-삽입의 경우 쓰지않는 여분의 공간을 새로운 record를 위해 남겨둔뒤 삽입되면 나중에 재구성을 한다
delete의 경우, delete mark만 남겨놓고 재구성하는 방법이 있다.

Transaction file
수정된 내용을 임시로 저장하는 temporary unordered file : overflow나 transaction file이라고 부른다
-main file은 따로 존재하고 record가 overflow에 삽입되면 나중에 합치는 과정을 수행한다
-주기적으로 main,overflow를 합치는 작업을 해야한다
-삽입이 효율적이게 되지만, 검색이 더 복잡해진다
-최신정보가 필요하지 않은 경우, transaction file을 무시하고 main file에서 검색하는것이 대안이 될 수 있다
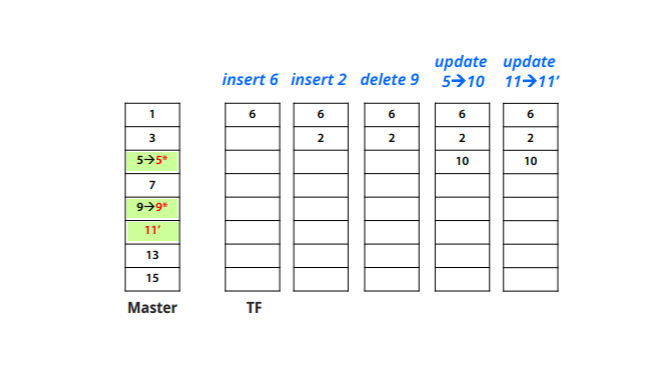

수정에 필요한 2가지 요인
수정할 record를 찾는다
-ordering key면 이진탐색, 아니면 선형탐색
수정하게 될 시
nonordering field : 그냥 고쳐서 그자리에 놓으면 된다
ordering field : old record 삭제, 수정할 record 삽입

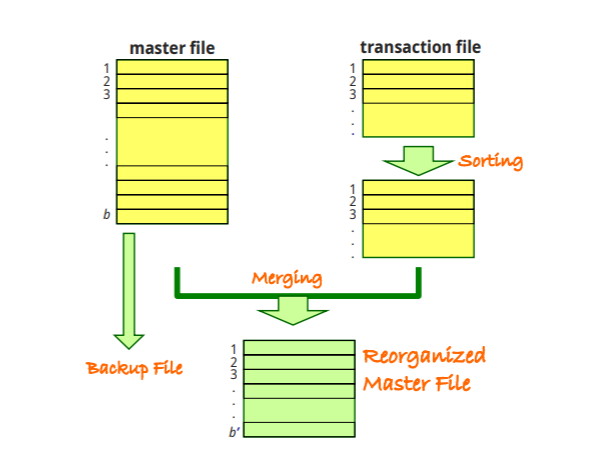
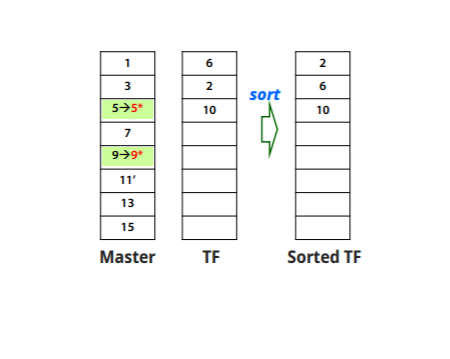
Reorganization : transation file이 커지면 부담이 되기 때문에, 합치는 작업을 한다
순서
1.transation file을 sort
2.main과 합친다

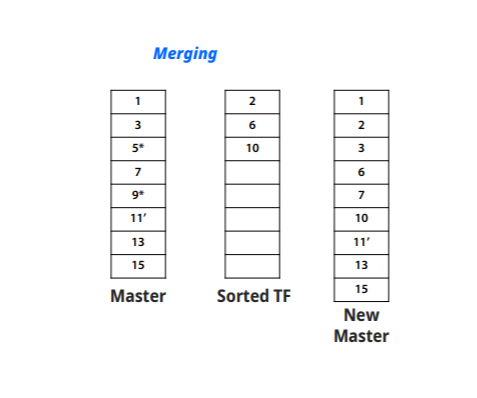
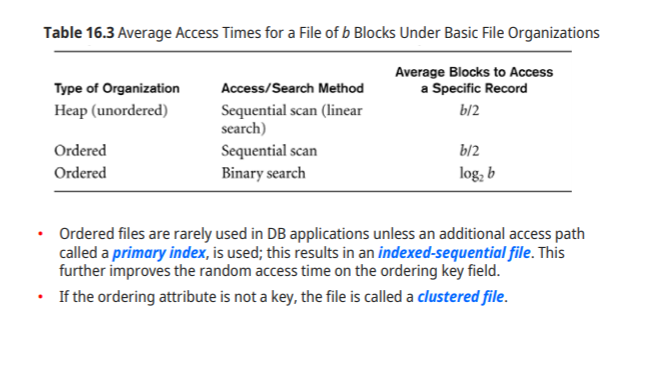
Heap : b/2
Ordered : Linear(b/2),binary(log)
-Ordered file은 primary key에 대한 index를 제공하는데, 이런 file 구조를 indexed-sequential file이라고 한다.
-Ordering attribute가 key가 아니면, 그 파일을 clustered file이라고 한다.


Hashing : Hash file, Direct file
-Primary file organization, 매우 빠른 접근 제공
-hash field(hash key)를 이용해 검색
-hash function h 존재
-해당 block을 찾으면 main memory로 가져와서 찾는다

Internal Hashing
hash table이 main memory주소를 찾아주는것을 말한다
해쉬 함수 : 해쉬 필드값 -> 0~(mm-1)
H(k) = kmodM
-정수형이 아닌 hash field value는 정수로 변환될 수 있다.

Collision
해쉬 함수의 문제
-키값에서 항상 서로 다른 주소가 나온다는 보장이 없다
-hash field space가 address space보다 크기 때문에 문제가 발생한다

Collision resolution : 충돌해결기법
3가지 방법
-개방 주소법
-Chaining
-다중 해싱방법

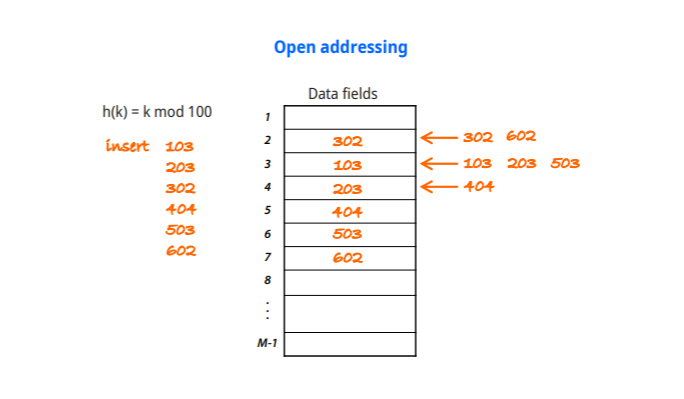


Multiple hashing
-hashing function을 하나 더 이용한다, 충돌이 발생하면 function을 통해 새로운 주소를 준다
어떤 것을 쓰든지 간에 검색,삽입,삭제를 위한 알고리즘이 따로 존재해야한다

좋은 hasing function
충돌이 적게 일어나도록 데이터를 골고루 퍼트리는것이 좋은 hasing function이다
-가장 좋은 방법은 전체 기억공간의 70~90프로를 차지하도록 해야한다, 공간의 낭비도 줄이고 충돌도 막는 가장 좋은 밀도
-mod의 M을 소수를 이용한다
-경우에 따라서 2의 m승 형태의 hashing function을 쓴다

External Hashing for Disk files
디스크 파일에대한 hashing을 external hasing이라 한다
bucket : hashing function의 결과인 address space, 하나의 disk block이거나 연속된 block으로 이루어 질 수 있다
hasing function : key를 이용해 relative bucker number 생성
relative bucker number로 부터 실제 disk 주소를 만들어내기 위한 table을 별도로 유지한다
collision resolution : chaining의 변형방법 사용
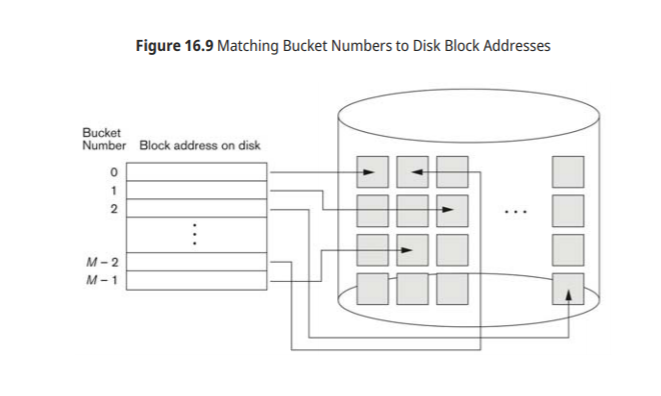
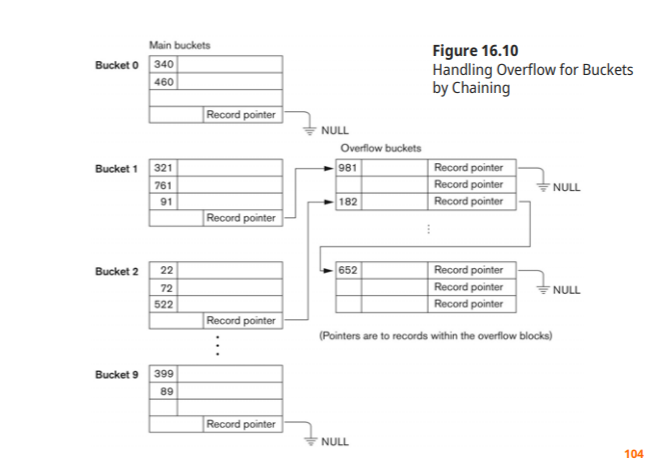

External Hashing의 연산
Searching : 해당되는 Hashing function을 써서 주소를 찾고 없으면 overflow chain을 따라가서 검색
delete : 해당 record 찾아가서 삭제, overflow 영역에 있으면 앞으로 땡겨오면 된다
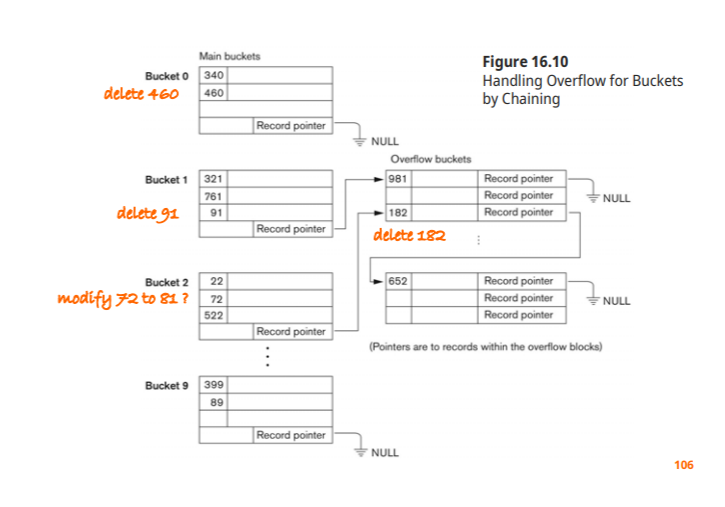

수정시 중요한 두가지 요소
1. 해당 record 검색
2.non hash field: 그냥 수정, hash field : delete 후에 새로 삽입

Static Hashing
static hashing : 처음부터 정해진 수의 버켓을 할당해놓고 record를 저장하는 방식
동적파일에서는 결함이 생김
-공간을 너무 크게, 너무 작게 잡으면 문제가 발생한다
해결책 reorganize : 재구성을 한다( 부담이 너무 큰 작업)

Hashing Techniques that allow dynamic file expansion
-extendible hashing
-linear hashing
-dynamic hashing
record의 hash 값에 대해 binary representation을 이용한 처리 방법들
-key를 2진수로 바꾸고 그 2진수 값으로 공간을 늘이고 줄인다

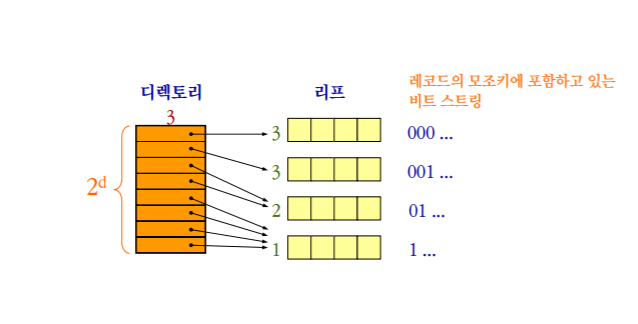
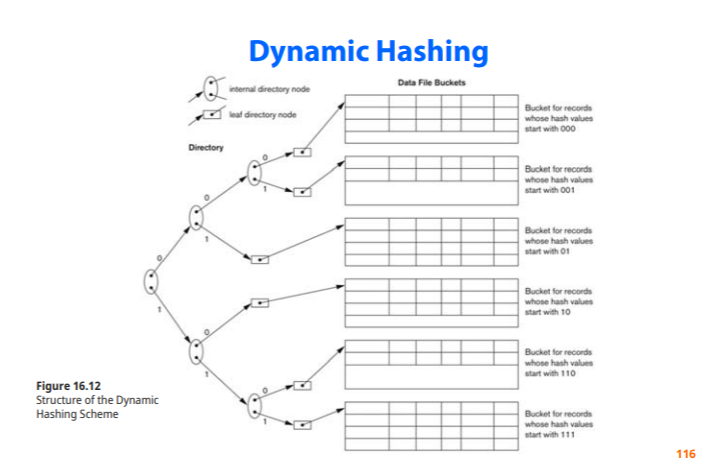
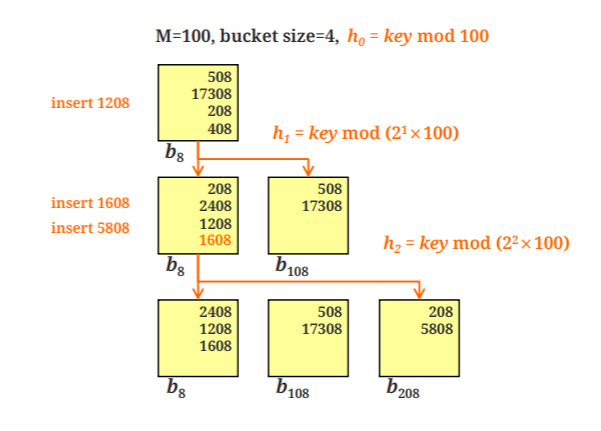
extendible hashing
키값을 2진수로 표현, 버켓은 2의d승개를 가진다
directory의 bit수는 Global depth
각 버켓의 bit수는 local depth 버켓의 local depth는 해당 되는 첫 비트가 같은 record들이 모여있다는 뜻이다


d는 data가 삭제되고 삽입됨에 따라서 늘수도 줄수도 있다.
d=d' 이면 doubling으로 증가
d>d' 이면 halving으로 감소

장점
file이 아무리 커져도 성능 저하가 발생하지 않음(디렉토리,버켓만 찾아가면 되기 때문)
미리 공간을 할당해놓을 이유가 없다 (필요하면 그때그때 늘리면 된다)
-디렉토리 공간의 오버헤드는 무시해도 될 정도
디렉토리나 버켓을 reorganization하는 것은 성능에 미미한 영향을 끼친다
단점
hash function이 주어지면 디렉토리를 가고 버켓을 찾는데 이 두번의 과정이 단점


RAID 기술
-처음에는 싼 디스크 여러개를 묶어서 큰 용량을 만들자는것이 목적이였다.
작은 여러개의 disk를 평행하게 묶어 하나의 커다란 고용량 disk같이 이용한다
-레이드 레벨0~6
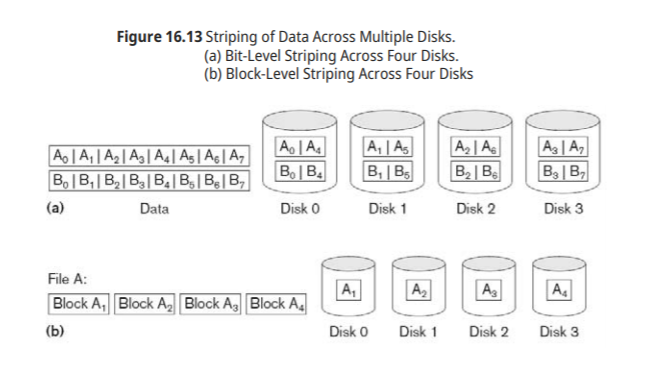
Data Striping : disk 퍼포먼스를 높히기 위해 data를 나누어서 저장한다
-bit level striping
-block level striping

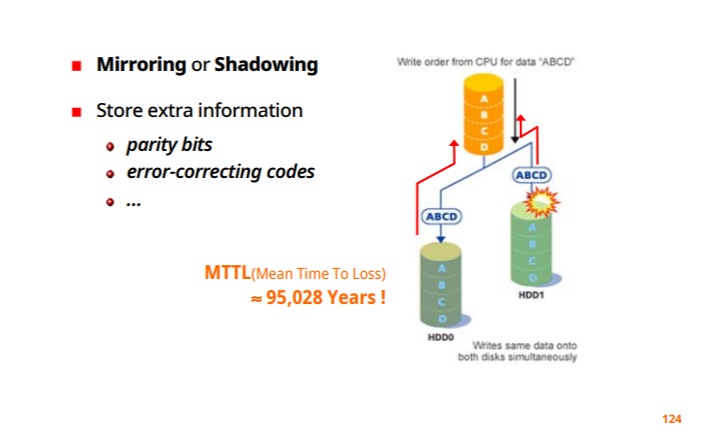
RAID를 통한 신뢰도 향상
n개의 disk를 갖는 array를 쓰게되면, 고장날 확률도 n배가 늘어난다.
-MTBF : 고장나지 않고 디스크를 사용할수 있는 시간
-100개의 디스크 드라이브 사용시 그 배수만큼 시간이 줄어든다
redundancy를 이용해 해결할 수 있으나
write를 위한 연산 추가해야하고
redundancy를 관리하기 위한 비용이 들고, 추가적인 용량이 필요하다

RAID를 통한 수행능력 향상
-disk mirroring(신뢰성면에서 향상)
-data striping (속도면에서 향상)

RAID 구성 방법
신뢰성과 속도면 두가지 요소를 적절히 고려하여야 한다
-data interleaving ( 속도)
-redundant information (신뢰성)
표준 RAID 레벨 0~6
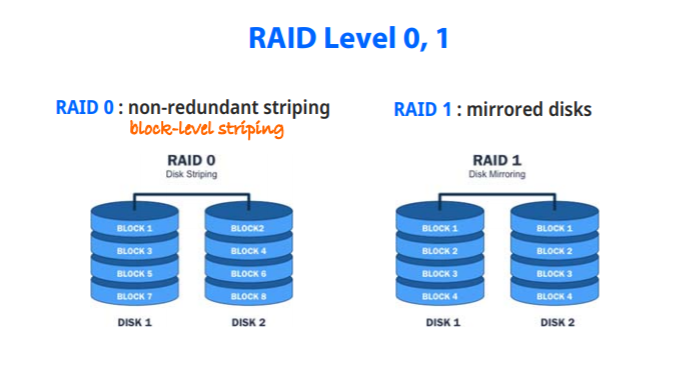
RAID Level 0,1
RAID 0 : redundant가 없고 block-level -striping 존재 (한번에 두 블럭씩 읽을 수 있어 속도면에서 향상)
RAID 1 : mirrored disks, 하나가 완전히 망가져도 나머지 하나 이용 가능(매우 높은 신뢰성)
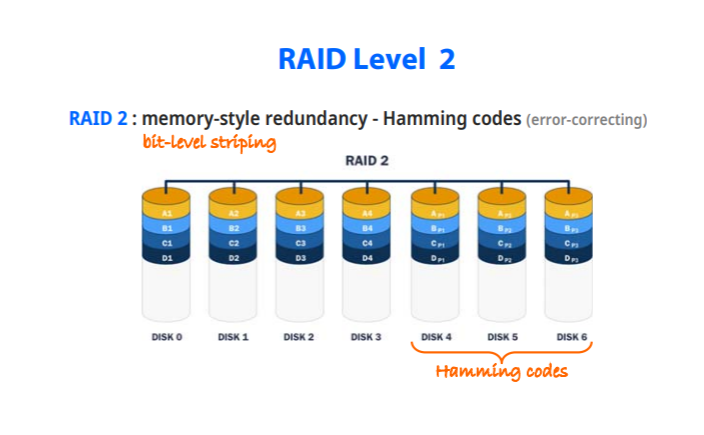
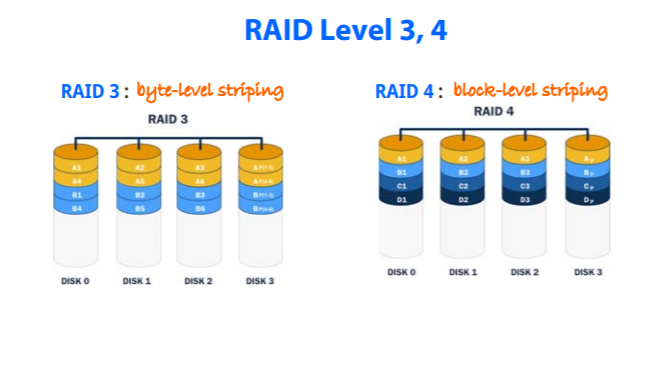
RAID 3,4
RAID 3: byte-level-striping , 2와 다르게 parity bit 하나만 이용(요즘 디스크는 어디가 고장났는지 위치를 아는것이 가능)
RAID 4: block-level-striping
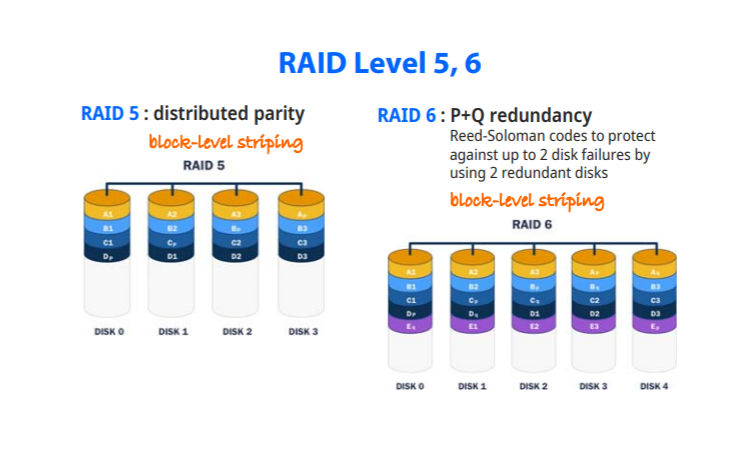
RAID 5,6
RAID 5: 3,4의 경우 계속된 참조때문에 parity bit가 있는곳에서 성능 저하가 발생, block-level-striping을 쓰면서 parity bit를 분산시켰다
RAID 6 : redundant disk를 2개를 사용 동시에 2개의 disk failures도 감당해야한다. parity bit를 두가지를 사용하며 가장 안정적이나 많이 쓰이진 않는다
0,1,5가 가장 많이 쓰이는 방법
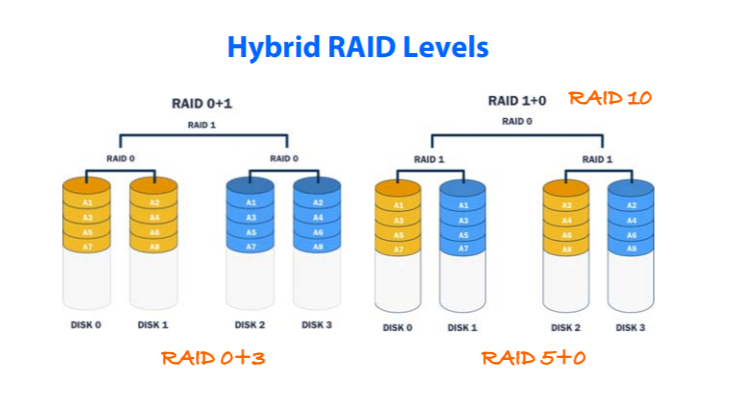
'Database' 카테고리의 다른 글
| Database 20장 (0) | 2020.12.01 |
|---|---|
| Database-17장 (0) | 2020.11.15 |
| Database-16장 (0) | 2020.10.22 |
| Database - 10장 (0) | 2020.10.22 |
| Database 14장 (0) | 2020.10.22 |



