

Two-Phase Locking Techniques
mutual exclusion을 제공하는 기법 locked, unlocked
Locking protocol (rules)
1.Transaction 내부의 x에대해 read,write를 하려면 lock을 해주어야 한다
2.Transaction이 종료되기전에 걸어놓은 lock이 있으면 풀어주어야 한다
3. 다른 Transaction이 lock해놓은것에 또 lock을 할 수 없다
4. 다른 Transaction이 lock해놓은 object를 풀 수 없다

Lock table
-lock manager subsystem이 lock된 data에 대한 정보를 기록하기 위한 table
-lock하나에 하나의 record가 저장되있다
lock(binary-valued variable)
-기다리는 transaction에 대한 queue를 가짐

Shared/Exclusive Locks ( Lock의 두 종류)
-Multiple mode lock
shared/exclusive = read/write lock
-Lock modes
read : shared lock, item read 공유해서 읽기만
write : exclusive lock , item write 혼자서만 읽기/쓰기

-shared locking protocol
1. Transaction 내의 X를 읽기위해선 read,write lock 둘중 하나를 해주어야한다
2. Transaction 내의 X를 쓰기 위해선 반드시 write lock을 해주어야 한다
3. read, write연산이 끝나면 unlock해야 한다.
4. data item에 대해 read,write lock이 존재하면 추가적인 read lock이 불가능
5. data item에 대해 read,write lock이 존재하면 추가적인 write lock이 불가능
6. 다른 Transaction이 걸어놓은 lock을 unlock할수 없다
4,5 번은 경우에 따라 바뀔 수 있는 규칙 downgrading/upgrading 되도록 .
이런 Locking을 사용한다 하여 serializable이 보장되는 것은 아니다

Multi mode Lock table
Lock(x) = write-locked, 한개의 transaction 만 lock write하는게 가능 (No_of_reads = 1 ,Locking _transactions =1)
Lock(x) = read-locked, 여러 transactions들이 lock을 걸어서 read 가 가능 (No_of_reads = n ,Locking _transactions = T1...Tn)



Two-Phase Locking protocol (2PLP) : 2단계 locking protocol
growing phase - 한번 lock을 걸으면 계속 lock을 걸어야 한다
shriking phase - 한번 lock을 풀면 새로운 lock을 할 수 없다
위 규칙을 지킬 시 모든 transaction이 serializable하게 나온다
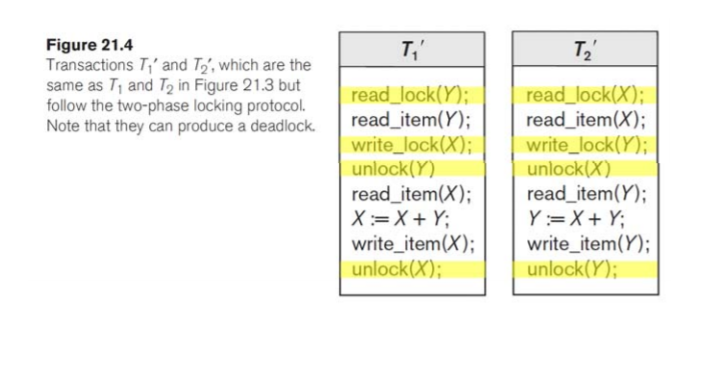
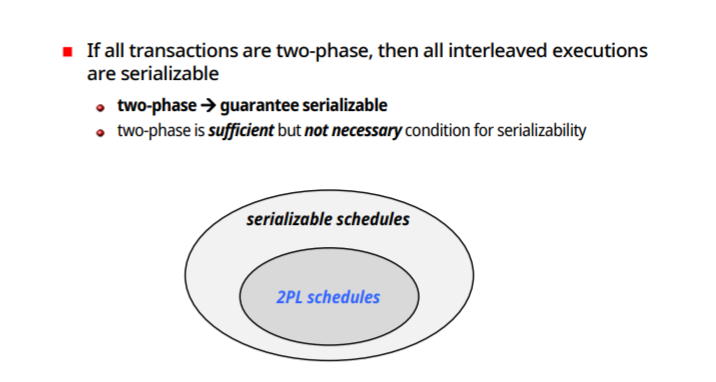
모든 T가 2PLP방식을 지키면 반드시 serializable하다
-two-phase -> serializable 보장
-two-phase는 충분조건이지 필요조건은 아니다. Why? 지키지 않아도 serializable한것이 있으니까

Basic 2PL
Conservative 2PL( static 2PL)
read set , write set을 미리 선언하고 그 item들을 모두 Lock을 구해놓는다
장점 : deadlock-free protocol (어떤 자원을 기다리는일이 없음)

Strict 2PL
commit이나 abort 될때까지 write lock을 풀어주지 않는다
recoverability : commit이나 abort전에 읽은 data는 dirty data가 된다, 그래서 S2PL은 이것을 허용하지 않는다
dead lock free는 아닌 방식이다
Rigorous 2PL
strict schedule을 보장해준다
commit이나 abort전에 shared lock (read lock)을 unlock해주는것 조차 허용해주지 않는다. (S2PL보다 더 엄격)
구현이 S2PL 보다 좀 더 쉬우나 융통성이 떨어진다

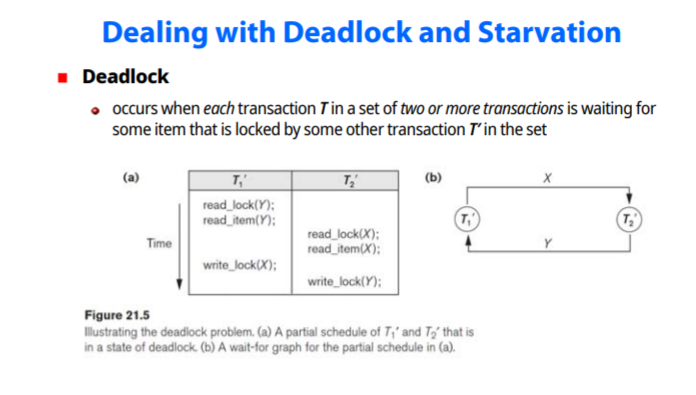
Dealing with Deadlock and starvation
locking기법 사용시 발생하는 deadlock 문제해결, 특정 transaction이 반복 abort되는 starvation문제
그림 T1은 T2의 X, T2는 T1의 Y를 기다리게 된다, 둘 사이에 cycle이 존재하여 deadlock 발생

Treatment
-prevention : 미리 예방
-avoidance : 런타임에 deadlock이 발생하지 않게 회피
-detection : 일단 수행하다가 deadlock 발생시 해결

Deadlock Prevention protocols
C2PL
-필요한것을 전부 확보해놓고 시작
-처음부터 필요한것을 얻는것은 엄격한 방식이다
DB의 item에 순서를 정함
-sorting된 순서대로 데이터를 처리
-현실적으로 쉬운 방법은 아니다

Transaction timestamp
timestamp : transaction이 시작된 시간
TS(T1)<TS(T2) : T1이 T2보다 먼저 시작되었다
Deadlock prevention schemes
-wait-die 방식, wound-wait 방식

Tj에 의해 lock된 X에 대해 Ti가 요청하는 상황
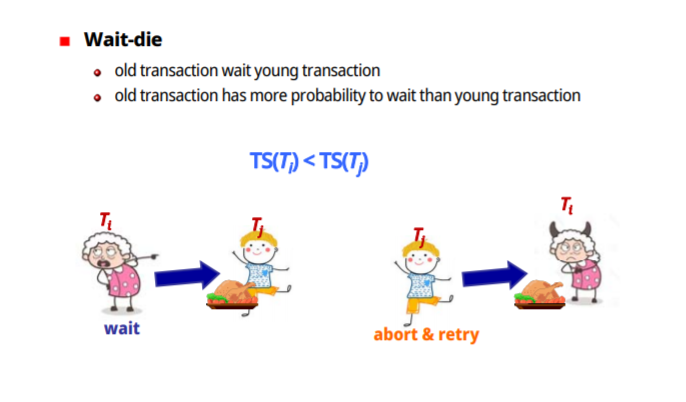
-Wait-die
Ti가 Tj보다 더 오래된 transaction이라면 기다리게 허용해 준다
그렇지 않으면 Ti를 abort시키고 같은 timestamp로 나중에 재시작한다
old T가 young T를 기다린다
old T는 young T보다 기다릴 확률이 더 높다
(아이가 음식을 먹고있으면 어른이 기다리고, 어른이 음식을 먹으면 아이는 나가있다가 나중에 온다(timestamp 적용))
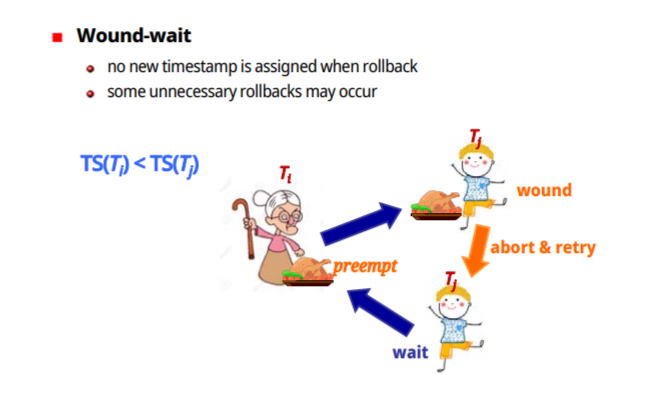
-Wound-wait
TS(T1)<TS(T2) 어린 transaction T2를 abort 시킨뒤 x를 T1에게 넘겨주고 같은 timestamp로 나중에 재시작한다
불필요한 rollback이 생기는 경우가 존재한다(처리가 곧 끝나는데, 뺏어가는 경우)
(아이가 음식을 먹고있으면 어른이 뺏어간다, 아이는 나가있다가 나중에 온다(timestamp 적용))

Deadlock Prevention Protocol without Timestamps
No waiting algorithm
lock 요청시 얻을 수 없다면, 바로 abort 시켜버린뒤 특정 time delay이후 재시작한다(deadlock체크 안함)
불필요한 abort와 transaction 재시작이 너무 많아진다

-Cautious waiting algorithm
불필요한 abort/restart를 줄이기위한 방법
rule : Tj에 의해 잠긴 X를 Ti가 요청할때 Tj가 blocked되지 않았다면 ti가 blocked되고 waiting을 허용
그렇지 않으면 Ti abort
blocked : transaction이 다른 item을 기다리고 있는 상태

deadlock free
b(T) : T가 blocked된 시간
만약 Ti,Tj가 둘다 blocked이 되었고 Ti는 Tj를 기다린다면 b(Ti)<b(Tj)가 된다
(Tj가 먼저 blocked되있었다면 Ti는 abort 당했을테니까, 위 예시는 Tj가 더 나중에 block됬다는 뜻)
모든 blocked T에 대해 block time은 정렬이 되있을 것이고 cycle, deadlock이 발생하지 않는다
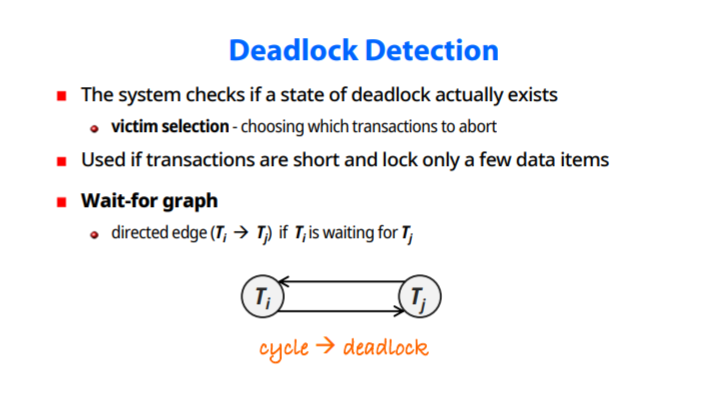
Deadlock Detection
deadlock 발생시 조치
-victim selection : 희생양 골라서 abort
transaction이 짧고 소수의 item이 lock됬을때 사용한다


Recovery
select victim : cost가 가장 적게 드는것을 고름(update가 없거나, 짧거나, 시작한지 얼마안된 T)
rollback : abort and restart
-partial rollback (잘 지원하지 않음)
starvation(livelock) : 같은 희생양이 계속 희생되는 상황 ,FCFS로 해결해 줄 수 있다

Granularity of Data Items and Multiple Granularity Locking
기본적으로 동시성 제어 기술은 모든 data item이 이름이 있다는것을 가정한다
locking의 단위가 커질수록 management overhead는 작아지지만, 동시성도 낮아진다
어떤 단위로 정하느냐에 따라 동시성 제어와 recovery에 큰 영향을 준다
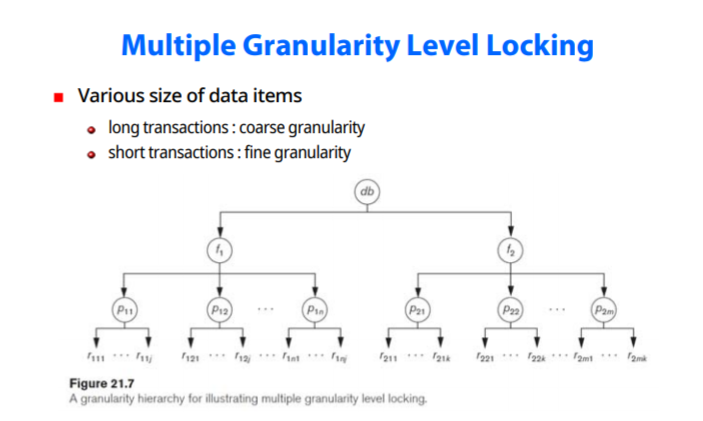
Multiple Granularity Level Locking
data items의 사이즈가 다양하다
long transactions : 단위를 크게
short transactions : 단위를 작게
db전체단위, file단위, record단위등 처리가 가능

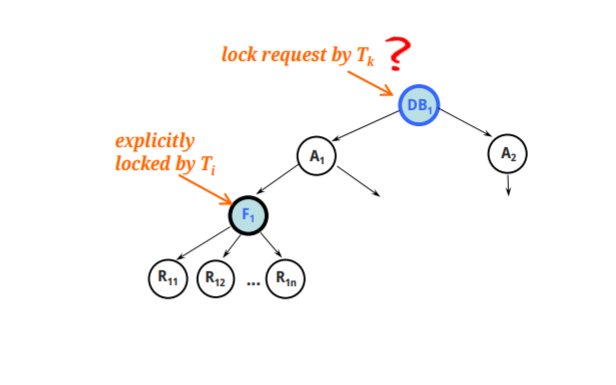

To lock a node N explicitly
-Node N의 모든 조상들에 대해 intention lock을 걸어준다
-N의 자손들은 implicitly lock이 된다.
DB내 특정 N에 대해 Lock걸리면 위로는 intention lock, 아래는 implicitly lock이 되어 만약 어떤 T가 DB에 Lock을 요청할때 intention lock이 되어 있는것을 보고 요청을 취소한다

Timestamp Mechanism
transaction이 시작된 순서대로 실행될 수 있게 보장해주는 기법이기에 deadlock이 발생하지 않음
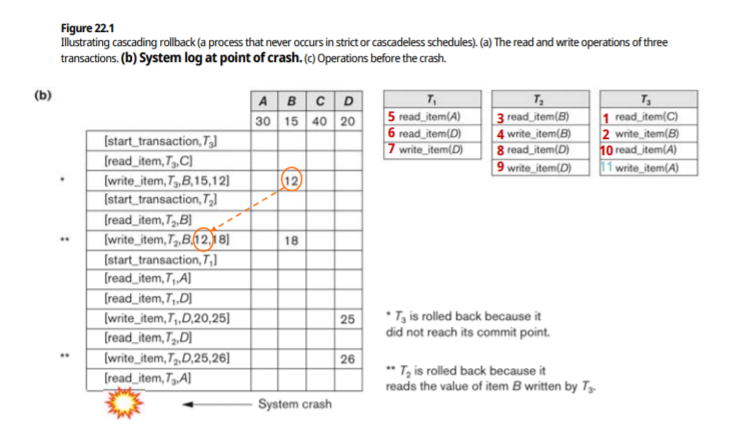
오래된 T가 젊은 T가 읽어간 내용을 access하려면 abort하고 restart(새로운 timestamp 부여, 오래된 T가 젊은 T가 write한것을 Read하는 상황, 시간적 매칭이 불가능)
cascading rollback : 오래된 T 때문에 젊은 T가 rollback 되는 경우가 있다
cyclic restart(starvation) : 연속적 rollback과 restart로 인한 starvation 발생가능

Multiversion Scheme
data item A에 대해, transaction에 대해 각각의 version을 생성한다
각 Version Ak에 대해, 두 timestamps를 유지한다
Write-TS(Ak): version 생성시간
Read-TS(Ak): 마지막으로 읽어간 시간
Idea
write(A): 새로운 버전 A 생성
read(A): 읽고자 하는 A의 가장 적합한 버전 제공 (serializable)

Recovery Concept
Database에 failure이 생겼을때 생기기전에 가장 최근의 consistent state로 복구시키는 과정
-System log 사용, system log : 다양한 T에 의해 바뀐 data item들에대해 정보를 저장해 놓은 곳
-lost information : 일부 data 손실이 발생할 수 밖에 없다 ( MM에 존재했던 data)
-consistent state : db에 error가 없고, inconsistencies한 상태가 없는 db


-일반적인 recovery 과정
1.catastrophic failure, disk crash (외부 요인)
-archival stroage에 있는 back up을 불러오고 back-up log정보를 이용해 다시 수행을 한다
2.noncatastrophic failure of types 1 thorught 4 (시스템적 요인)
-db의 program이나 error로 인해 inconsistency가 발생하는지 식별
-db의 item들에 대해 변화된 내용이 commit이 안된 상황에서는 undo작업을 통해 시작하기 전 상태로 돌려놓아야 한다.
-이미 commit된 것들은 redo 작업을 통해 consistent state of db를 복원한다
-두가지 방법이 존재한다 :, 지연갱신, 즉시갱신에 따라 recovery 전략이 달라진다
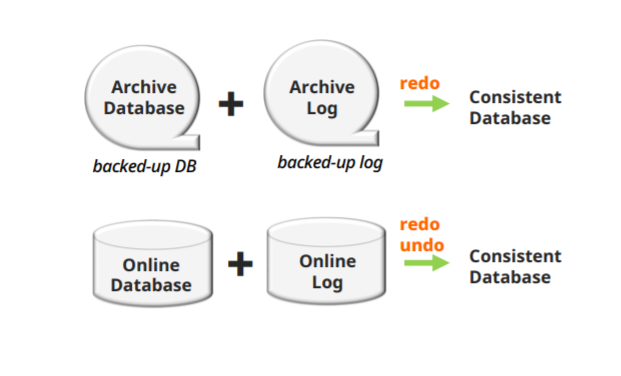

Caching of Disk Blocks
disk block의 caching, buffering 문제는 recovery 절차를 효율적으로 하기 위해 OS에 맡기는 경우보다 DBMS가 직접 처리하는 경우가 많다
-main memory에 들어온 buffer들을 DBMS cache라고 하며 보통 DBMS가 직접 관리한다
-directory도 같이 관리한다
Buffer replacement(flush) : disk로 나가고 새로운 block이 읽혀들어오는 과정
dirty bit : buffer의 block내용이 수정이 됬는지에 대한 bit
pin-unpin bit : pin이 되있으면 쓰고 있으므로 flush x, unpin상태면 필요시 disk로 flush

수정 buffer를 disk로 flushing 하는 2가지 방법 존재
in-place updating : 해당 disk block을 buffer(MM)로 가져오면 나중에 돌려보낼때 원래 자리로 보내는 방식
shadowing : 해당 block을 buffer(MM)에 넣고 수정시 새로운 block에 writing(BFIM : 이전값, AFIM : 수정값)

Steal/No-steal and Force/No-force
DBMS cache들을 disk로 flushing 하는 전략
Steal/No-steal
Steal : commit 되기전에 disk로 flush할 수 있느냐
No-steal : steal을 허용하지 않는다
Force/No-force
Force : T가 commit되면 commit되는 순간에 T가 수행한 갱신내용을 Db에 강제로 반영 시키느냐
No-force : Force를 하지 않는다
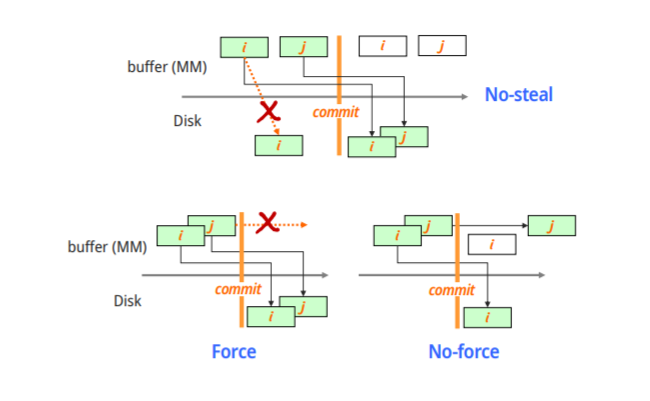
No-steal : commit되기 전까진 disk로 flushing하지 않음
Force : commit되면 그 순간에 강제적으로 갱신내용을 disk로 write
No-foce : commit된 후에 갱신된 내용을 강제로 disk로 보내지 않고 Os buffer manager가 알아서 처리하게 두는 방식
방식에 따라 recovery 전략이 달라진다

전형적인 db는 steal/no-force 전략 사용
steal 장점 : 필요에 따라 commit 되지 않은 buffer들을 disk로 내보내고 빈buffer로 만드는것이 가능 (메모리 활용 유연)
no-force : commit된 후에 바로 block을 없애지 않으면 다른 T가 그 block이 필요할때 다시 읽어들이는 과정이 생략된다(I/O 연산에 대한 save)
deferred update : db에 대한 내용을 commit전까진 db에 반영하지 않음 (no-steal 방식)

Write-ahead Logging
buffer을 disk로 내보낼때 원래 있던 자리에 쓸지(in-place) , 다른 자리에 쓰는 shadowing 방식 존재
in-place의 경우 덮어쓰기 때문에 undo,redo의 상황에 대비하여 log를 가지고 있어야 한다
Log entry : Undo,Redo를 위한 정보
Redo : commit된 상태에서 재 작업을 해주는 과정
Undo : commit 전에 작업을 하기 전 상태로 돌리는 과정
Redo-type log entry : 다시 수행해주면 되므로 AFIM만 가지면 된다
Undo-type log entry : 예전 상태로 돌려야하므로 BFIM만 가지면 된다

log는 순차적으로 추가만하는 disk file
-log record가 쓰이면, DBMS cache내에 log buffer형태로 저장
-DBMS cache는 MM buffer내에 여러 log block들을 포함한다
-해당 되는 data block이 갱신되면 log record도 DBMS cahce의 log buffer로 flusing 해주어야 한다

X->X'로 바꿨다는 사실, log buffer 또한 같이 생성을 해주고 data buffer을 내보내고 disk내 log file에 log도 write를 한다.
이때 data buffer을 먼저 내보낼지 log buffer을 먼저 내보내는지에 따라 결과가 달라지는데
data buffer가 기록이 안되있어도 Log기록을 통해 redo나 undo가 가능하기 때문에 log buffer을 먼저 내보낸다.

write-ahead logging(WAL) protocol : in-place 갱신시 가장 중요한 recovery 알고리즘
1.BFIM이 AFIM으로 갱신 되어야 하는데 log가 먼저 출력되기 전까진 갱신될 수 없다.
2.commit 연산은 commit전까지의 모든 log를 disk로 내보내야 data commit이 가능하다.





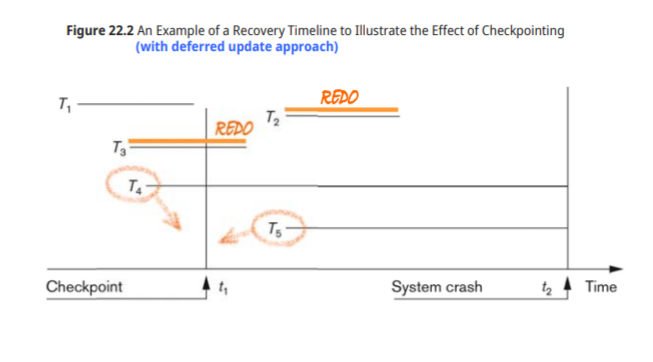
NO-UNDO/REDO Recovery Based on Deferred Update
deferred update는 commit 전까지 update를 하지 않으므로 undo가 필요없고, redo 연산만이 필요하다.
partial commit이 될때까지 모든 연산들을 연기한다
-Redo type log만이 필요하다 (AFIM)
-no-steal
-transaction이 짧고, update가 거의 없는 경우에 쓸 수 있다
-실용적이지 못한 이유는 결국 transaction이 commit 되기전까지 모든 transaction이 사용하는 buffer들을 pin상태로 두어야 한다.(buffer영역,메모리 많이 차지)
Log record에 old value는 필요가 없음!




Recovery from Failure
commit된 후의 error
-확인 차원에서 Redo한번만 해주면 된다
commit전 error
-재시작

Execution of REDO
Log1 : commit 전이므로 재시작 => no recovery action
Log2 : T1 commit 후 log는 있고, db에 기록이 누락 되있을수도 있으므로 REDO(T1)
Log3 : Redo(T1),Redo(T2)

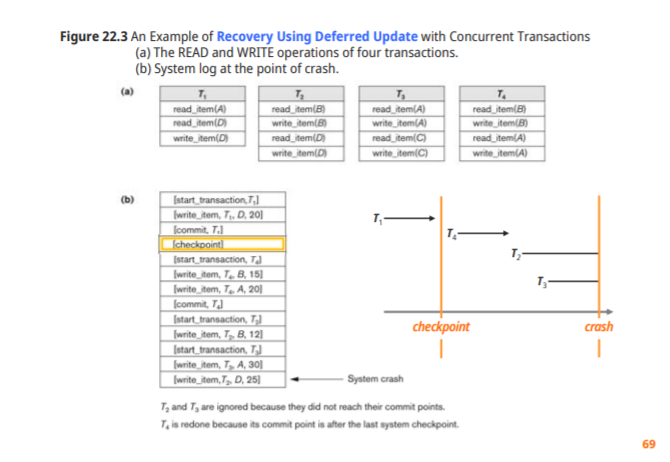
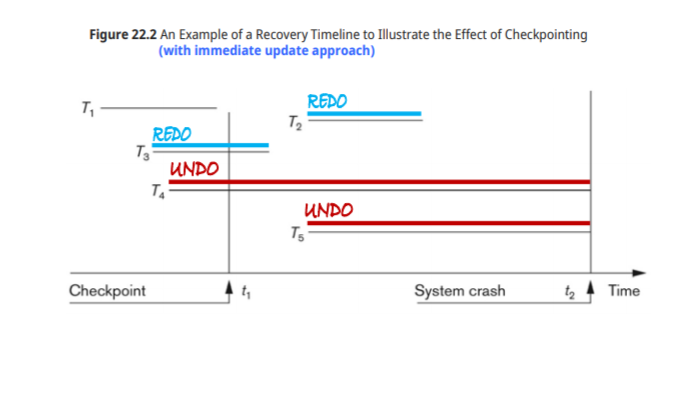
Recovery Techniques Based on Immediate Update
uncommitted update : steal 방식
Log record : old value, new value 두가지 필요

Recovery from Failure
commit 전 error
-undo 작업을 통해 없던 일로 만들어줘야 한다
commit 후 error
-redo 작업으로 확인

A<-900에서 failure이 발생하면 disk에 900이 들어갔는지 안들어갔는지 확실히 모르기 때문에 undo를 통해 1000으로 바꾼다
T1이 commit된 후 failure이 발생하면 Redo 작업을 통해 A,B값을 재확인하고 기록이 안되있을시 new value를 써준다
T2 commit전 failure이 발생하면 Redo T1, undo T2를 한다

Checkpoints in the System Log and Fuzzy Checkpointing
어느 시점까지 거슬러가야 할지 모르기 때문에 사용하는 checkpoint 기법
Checkpoint entry in the log
-checkpoint전의 commit이 있었던 모든 transaction에 대해서는 write연산이 disk에 확실히 기록을 했다는 확인작업을 했기 때문에 redo작업을 할필요 없다
-정해진 시간마다, commit된 transaction 개수마다 두가지 방식으로 checkpoint를 정한다
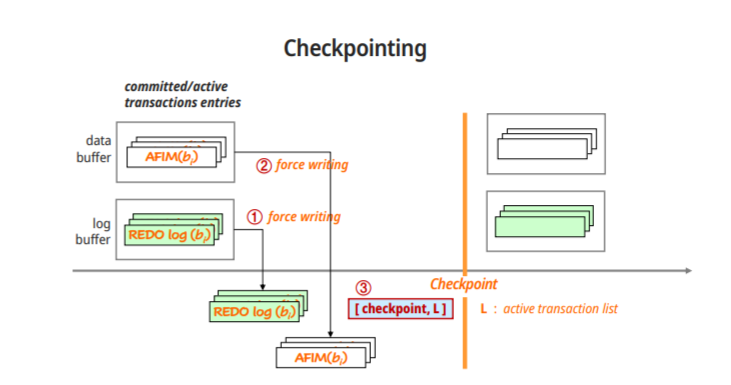

1.현재 수행되고 있던 모든 T를 중단시킨다
2.모든 memory buffer내용을 disk로 내보낸다
3.checkpoint log record를 기록한다
4.T 수행 재개


Paging shceme
page : 고정길이 disk block
DB는 page로 나누어져 있다
핵심
file을 두 페이지 테이블로 유지한다
-current page table
-shadow page table
1. page i 읽고
2. 갱신하고
3. 새로운 page 장소에 갱신값을 적고
4. current page table로 가리키게 한다
shadow page table은 transaction 수행중에는 변경되는 경우가 없다
transaction 수행이 끝나면, current 가 shadow가 된다
만약 실패시, current를 버린다
-log 필요x
-undo 필요x
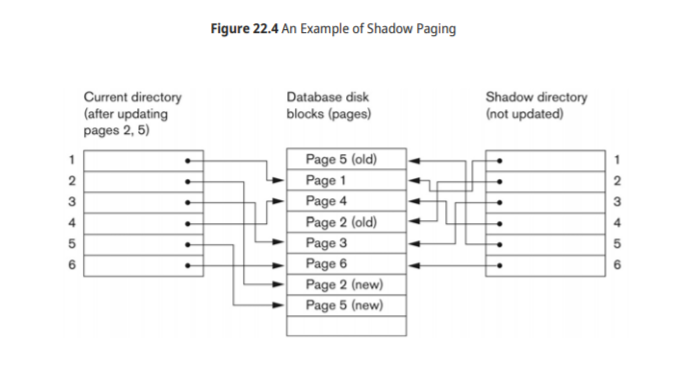

장점
log record를 저장하는 overhead가 안든다
recovery가 빠르다
undo나 redo가 필요없다
단점
Data fragmentation : 단편화 발생
Garbage collection : 이전 page에 대한 garbage collecting

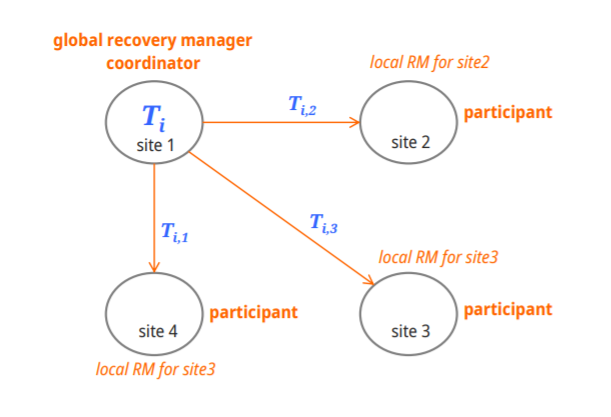
Recovery in Multidatabase Systems
Multidatabase에선 multidatabase transaction이 생기게 된다
여러 db의 협력하에 transaction이 수행 ( atomic 보장해주어야 한다)
atomicity는 two-level-recovery mechanism으로 보장해준다
-global recovery manager, coordinator => 전체 transaction 보장
-local recovery manager => 자기 자신 local지역 transaction 보장
two-phase commit protocol(이단계 완료 규약)을 따른다

기본
atomicity : 모든 site가 똑같이 commit하던지 abort하던지
participant : 참여하는 site
Protocol
Si에서 시작을 했다면 Si가 transaction coordinator가 된다
모든 participants가 수행이 끝나면 protocol이 시작된다

'Database' 카테고리의 다른 글
| Database 20장 (0) | 2020.12.01 |
|---|---|
| Database-17장 (0) | 2020.11.15 |
| Database-16 (0) | 2020.11.05 |
| Database-16장 (0) | 2020.10.22 |
| Database - 10장 (0) | 2020.10.22 |



